99 Deduplication Problems
| Venue | Category |
|---|---|
| HotStorage'16 | Deduplication |
1. Summary
Motivation of this paper
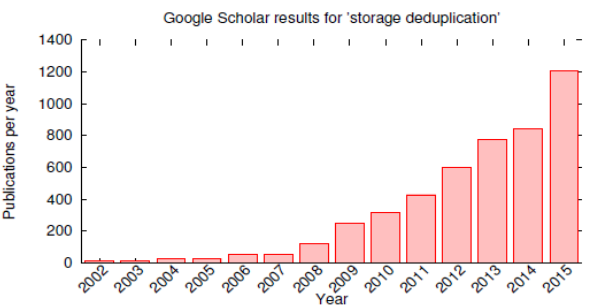
Most deduplication-related publications focus on a narrow range of topic:
maximizing deduplication ratios read/write performance
This papers believes that there are numerous novel, deduplication-specific problems that have been largely ignored in the academic community.
99 Deduplication Problems
- Capacity
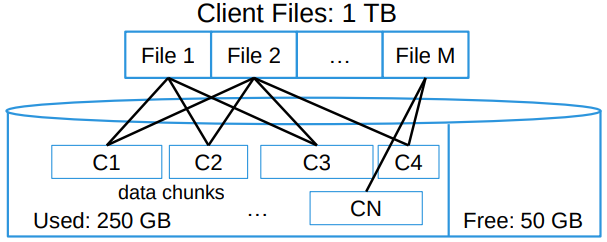
non-deduplication system: a fairly straightforward to answer this kind of question since such systems How to write data? (the logical write value is not real value that to write) How to delete data? (the logical free value is not the real return value) A deduplication system is dynamic, it is hard to track a file in real time
an intuitive way is collected information periodically.
Future Research Opportunities:
- Offline process: periodically calculate the unique content for each file
- Inline process: provide hints about capacity that are at least accurate within an approximation threshold.
- Estimation size: estimation tools, capacity usage, performance, network usage
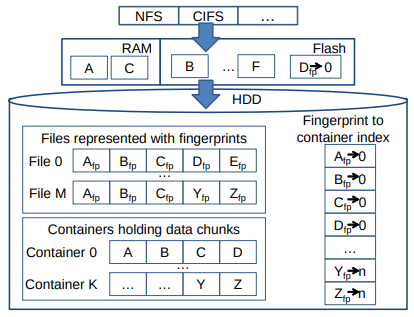
- Quality of Service A deduplication storage system should also meet the requirement regarding to quality of service for a client.
latency, throughput Root reason: adds additional levels of indirection to map from a file representation to the data chunks locations. Performance drop off: turn sequentially written content into references to chunks scattered across the HDDs.
Future Research Opportunities
- Restore performance
- Garbage collection
- arware the potential latency of various operations
- QoS: latency, throughput, and priority level
Shared content creates unpredicatable performance.
- Security and Reliability Maintain advantages of deduplication while securely storing data, preventing
- Unauthorized access
- Knowledge of content
- Data tampering
By timing data transfers, it may also be possible to infer what already exists on a deduplicaion servers.
Reliability the complex relationship between deduplication and data reliability.
Intuitively, the combination of RAID, versioning, and replicating counterbalances a risk of data loss due deduplication How to quantitatively analyzing the reliability?
Future Research Opportunities
- complete an empirical measurement of data loss rates for various flavors of deduplicated storage.
needs vendors to release such information
- model the risk of each component of the system using published failure characteristics and calculate the reliability for the storage environment.
- Chargeback for service providers
Future Research Opportunities
- need to accurate measurements for post-deduplication resource usage (capacity, I/O, network, etc.)
4. Future Works
After reading this paper, I can get a high level picture of potential research topics in deduplication area. Some points can be followed
Security and reliability Capacity measurement