Accelerating Restore and Garbage Collection in Deduplication-based Backup Systems via Exploiting Historical Information
| Venue | Category |
|---|---|
| ATC'14 | Deduplication Restore and GC |
Accelerating Restore and Garbage Collection in Deduplication-based Backup Systems via Exploiting Historical Information1. SummaryMotivation of this paperMethod name Implementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some Insights
1. Summary
Motivation of this paper
- Motivation
- The identification of valid chunks is cumbersome and the merging operation is the most time-consuming phase in garbage collection.
identify valid chunks and the containers holding only a few valid chunks.
Merging operation: copy the valid chunks in the identified containers to new containers, then the identified containers are reclaimed.
most time-consuming phase in garbage collection.
- Most of current approaches rewrite chunks belong to out-of-order containers, which limit their gains in restore performance and garbage collection efficiency.
Observation
- reducing sparse containers is important to address the fragmentation problem.
- two consecutive backups are very similar, and thus historical information collected during the backup is very useful to improve the next backup.
Method name
- Fragmentation Classification fragmentation come in two categories:
sparse containers out-of-order containers
- Sparse containers it defines container utilization for a backup as the fraction of its chunks referenced by the backup.
define a threshold, if the utilization is smaller than the predefined threshold, regard it as a sparse container. reduce sparse containers can improve the restore performance.
- Out-of-order container A container is accessed many times intermittently during a restore, it considers it as an out-of-order container for the restore.
cause by the self-referred chunk. reduce the restore performance if the cache size is smaller that the cache threshold have no negative impact on garbage collection
- Key question How to reduce sparse containers becomes the key problem.
Observation: sparse containers of the backup remain sparse in the next backup.
- System architecture
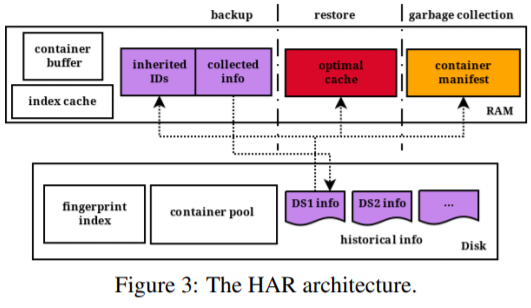 Use a data structure to track all containers:
Use a data structure to track all containers:
(container's ID, current utilization, pointer)
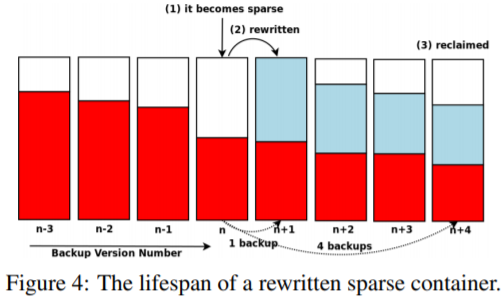
- History-aware rewriting algorithm Idea: rewrites all duplicate chunks in the inherited sparse containers. The effect depends on how many backups it needs to retain?
- Optimal restore cache Use Belady's optimal replacement cache
need to know the future access pattern
Collect access pattern information during the backup
since the sequence of reading chunks during the restore is just the same as the sequence of writing them during a backup. record the container ID
- Container-Marker Algorithm HAR naturally accelerates expirations of sparse containers and thus the merging is no longer necessary.
For each container, CMA maintains a dataset list that records IDs of the datasets referring to the container. If a container's list is empty, the container can be reclaimed.
Implementation and Evaluation
Dataset:
- VMDK, Linux, synthetic dataset
Metric
- average utilization
- deduplication ratio: outperform CBR and CAP in terms of backup performance.
- restore performance: speed factor
- garbage collection: reference management overhead, valid containers
- varying the utilization threshold: deduplication ratio, restore performance
2. Strength (Contributions of the paper)
- this paper classifies the fragmentation into two categories: out-of-order and sparse containers.
out-of-order containers reduce restore performance. sparse containers: reduce both restore performance and garbage collection efficiency.
- it proposes History-Aware Rewriting algorithm (HAR) to accurately identify and reduce sparse containers.
- it also proposes Container-Marker algorithm (CMA) to reduce the metadata overhead of garbage collection.
identifies valid containers instead of valid chunks in garbage collection.
3. Weakness (Limitations of the paper)
4. Some Insights
- The key of HAR is to maintain high utilizations of containers.
- In GC, the reference management is the key requirement, and HAR manages the reference in container level instead of chunk level.