BPF for Storage: An Exokernel-Inspired Approach
| Venue | Category |
|---|---|
| HotOS'21 | I/O optimization |
BPF for Storage: An Exokernel-Inspired Approach1. SummaryMotivation of this paperBPF for StorageImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some Insights (Future work)
1. Summary
Motivation of this paper
motivation
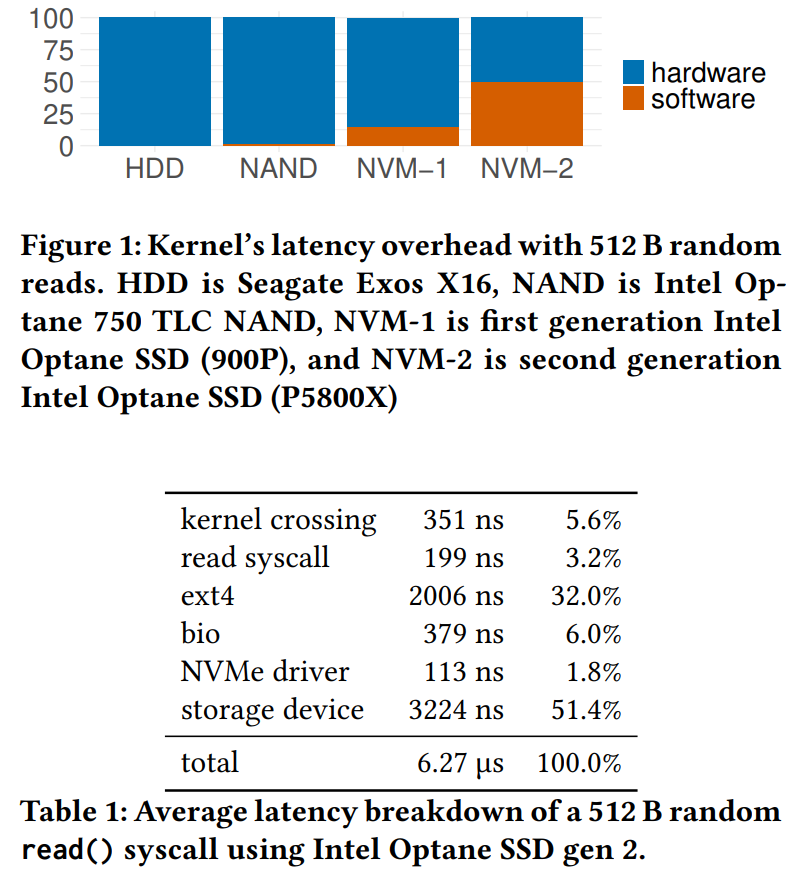
the overhead of the kernel storage path accounts for half of the access latency for new NVMe storage devices
using BPF: injecting user-defined functions deep in the kernel's I/O processing stack
bypassing kernel layers and avoiding user-kernel boundary crossings
a standard OS-supported mechanism that can reduce the software overhead for fast storage devices
problem
avoid losing important properties when bypassing the file system and block layer
translation between physical block addresses and file offsets
packets are self-describing
BPF can operate on them mostly in isolation
traversing a structure on-disk is stateful and frequently requires consulting outside state
BPF for Storage
BPF function
aims to eliminate nearly all of the software overhead of issuing I/Os
kernel-bypass
avoiding the pitfalls of kernel-bypass such as polling and wasted CPU time
main goal
allow applications to define custom BPF-compatible data structures and functions
traversing, filtering and aggregating on-disk data
work with Linux's existing interfaces and file systems
focus on immutable data structures with largely stable extents
software is the storage bottleneck
random 512 B read() with O_DIRECT on Intel Optane SSD Gen 2
BPF for storage
issuing dependent storage requests
occupy I/O bandwidth and CPU time to fetch data that is ultimately not returned to the user
benefit
B-tree
parsing the current page to find the offset of the next disk page
issue a read for the next page
the syscall dispatch layer: mainly eliminates kernel boundary crossings
the NVMe driver's interrupt handler
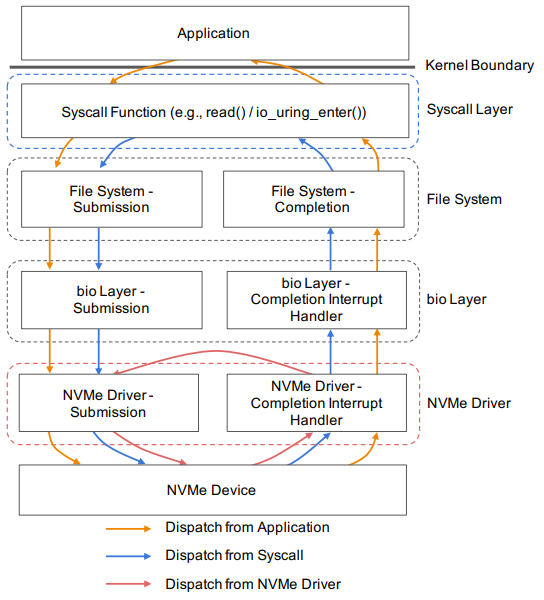
two hooks call an eBPF function that simply issues a memcpy, simulating parsing the page to find the next pointer
dispatch a random read I/O request for the pointer extracted by the BPF function
placing the hooks close to the device benefits both standard, synchronous read calls and more efficient io_uring calls
a design for storage BPF
these BPF functions that would be triggered in the NVMe driver interrupt handler on each block I/O completion
extract file offsets from blocks fetched from storage
reissue an I/O to those offsets
challenges
install a BPF function using a special ioctl
translation & security
imbuing the NVMe layer with enough information to efficiently and safely map file offsets to the file's corresponding physical block offsets
focus on cases when the extents for a file do not change
Implementation and Evaluation
2. Strength (Contributions of the paper)
new direction of using BPF to speedup storage operation
3. Weakness (Limitations of the paper)
4. Some Insights (Future work)
the software stack is now a substantial overhead
100 Gb/s bandwidth is now common for NICs
storage devices only support 2-7 GB/s bandwidth and 4-5 us latencies
near-storage processing
SPDK
wasteful busy waiting
kernel-bypass
allows applications to submit requests directly to devices
except the costs to NVMe driver
io_urings
batched and asynchronous I/O submission/completion path
amortizes the costs of kernel boundary crossings
avoid expensive scheduler interactions to block kernel
Berkeley Packet Filter (BPF)
efficient packet processing
eliminates the need to copy each packet into user space
filtering packets, network tracing, load balancing
envision a BPF for storage library
offload many other standard storage operations to the kernel
e.g., aggregations, scans, compaction, compression, and deduplication