Data Domain Cloud Tier: Backup here, backup there, deduplicated everywhere!
| Venue | Category |
|---|---|
| USENIX ATC'19 | Cloud Deduplication |
Data Domain Cloud Tier: Backup here, backup there, deduplicated everywhere!1. SummaryMotivation of this paperCloud TierImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some insights
1. Summary
Motivation of this paper
Object storage in public and private clouds provides cost-effective, on-demand, always available storage.
- Data Domain added a deduplicated cloud tier to its data protection appliances
- Its deduplication system consists of an active tier:
customers backup their primary data (typically retained for 30-90 days)
- It also contains a cloud tier:
selected backups are transitioned to cloud storage (retained long term 1-7 years)
- Motivation there were many architectural changes necessary to support a cloud tier in a mature storage product.
Cloud Tier
- Data domain cloud tier architecture
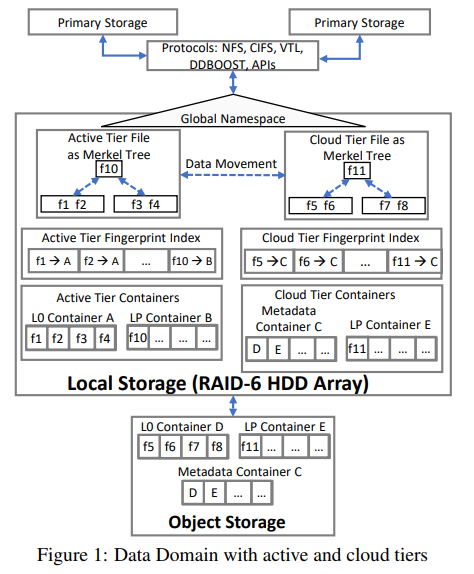
- Active Tier Architecture
- File is represented by a Merkle tree with user data as variable sized chunk at the bottom level of the tree. (referred as L0 chunks)
- SHA-1 fingerprint of L0 chunks are grouped together at the next higher level of the tree to form chunks. (L1 chunks)
- the top of the tree is (L6 chunks)
- LP chunks: chunks above L0 as LP chunks
- If two files are exactly the same, they would have the same L6 fingerprint. (if two files only partially overlap in content, then some branches of the tree will be identical.)
Metadata and data separation: L0-containers and LP-containers
the locality of L0 chunks is preserved which results in better read performance Each container: data section (chunk), metadata section (fingerprints of chunks)
- Cloud Tier Architecture Goal of cloud tier:
- use it as extra capacity
- use it for long term archival of selected data
Metadata container: it refers a third type of container, which stores the metadata sections from multiple L0 and LP-Containers
the metadata section of containers are reading during deduplication and garbage collection, and require quick access, so Metadata-Containers are stored on the local storage as well as in cloud storage. mirror the metadata
Main difference: store critical cloud tier metadata on the local storage of the Data Domain system to improve performance and reduce cost.
- Object Size (Container Size) it starts with 64KB objects, but evolved to large sizes in the range of 1-4MB for several reasons
larger objects result in less metadata overhead. also decrease transaction costs as cloud storage providers charge per-object transaction costs. terms objects and containers interchangeably.
- Perfect hashing and Physical scanning for the cloud tier
- Perfect hashing perform a membership query by representing a fixed key set.
a perfect hash function is a collision-free mapping which maps a key to a unique position in a bit vector. (1 : 1 mapping) a perfect hash function + a bit vector
- Physical scanning discuss how to walk the LP chunks of all or most of the files in the system.
how to traverse the Merkle tree enumeration is done in a breadth first manner
- Estimate freeable space
- traverse the merkle tree of selected files, mark the chunks in an in-memory perfect hash vector.
- walk all the remaining files, unmark the chunks referenced by these remaining files.
- the chunks which are still marked in the perfect hash vector are the chunks which are uniquely referenced by files selected.
- Seeding a one time process to transfer a large amount of data from the active tier to a nearly empty cloud tier. (need to generate perfect hash vector)
- used for migration of large amount of data to the cloud.
- guarantees that all the L0 and LP chunks are transferred to the cloud before the file's location is changed in the namespace. (using perfect hash vector)
- File Migration transfer a few files incrementally.
reduces the amount of data transferred to the cloud tier by performing a deduplication process relative to chunks already present in the cloud tier. do not need to generate perfect hash vector, directly scan Merkle tree.
- Garbage collection (GC) When customers expire backups, some chunks become unreferenced.
mark and sweep
- Active tier garbage collection after marking chunks live in the perfect hash vector, the sweep process walks the container set to copy live chunks from old containers into newer containers while deleting the old containers.
- Cloud tier garbage collection Since the L0 containers are not local and reading them from the cloud is expensive. It needs a way to do garbage collection without reading the L0-container from object storage and writing new L0-container to object storage.
need to implement new APIs in cloud providers. delete a compression region in a cloud container when it is completely unreferenced instead of individual chunk.
Implementation and Evaluation
- Evaluation
- Deployed system evaluation
GC analysis Cleaning efficiency loss due to compression region cleaning
- Internal systems
Freeable space estimation File migration and seeding performance Garbage collection performance File migration and restore from the cloud
2. Strength (Contributions of the paper)
- propose a new algorithm to estimate the amount of space unique to a set of files.
builds upon a previous technique using perfect hashes and sequential storage scans.
- develop a bulk seeding algorithm that also uses perfect hashes to select the set of chunks to transfer.
transfer the unique content to the cloud tier to preserve the benefits of deduplication during transfer.
- design collection scheme for the cloud tier
handle the latency and financial cost of reading data from the cloud back to the on-premises appliance.
3. Weakness (Limitations of the paper)
- For its cloud tier garbage collection, it needs to modify the internal APIs of the cloud providers.
4. Some insights
- This paper also mentions it is hard to calculate free up space by migrating files to the cloud
needs an algorithm to estimate the amount of space unique to a set of files.
- Something related to security Data Domain appliance tends to be utilized by a single customer, who typically selects a single encryption key for all of the data
have not found customer demand for convergent encryption or stronger encryption requirements for cloud storage than on-premises storage.
If multiple keys are selected, customers accept a potential loss in cross-dataset deduplication.
- How about disaster recovery? the main reason why the active tier and cloud tier have different deduplication domains. (each tier is a separate deduplication domain)
If an active tier is lost, the backup copies migrated to object storage can be recovered.
- The overhead of generating perfect hash In this paper, it mentions it is nearly 3 hours per 1PB of physical capacity.
suppose it is static fixed fingerprint set.