Estimating Duplication by Content-based Sampling
| Venue | Category |
|---|---|
| ATC'13 | Deduplication Sample |
Estimating Duplication by Content-based Sampling1. SummaryMotivation of this paperContent-based Sample Implementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Future Works
1. Summary
Motivation of this paper
The benefit of deduplication in a primary storage system varies for different workloads.
For a certain workload that have a low level of deduplication, one would to turn off the deduplication feature to avoid its effect on I/O performance and to avoid the metadata overhead of deduplication.
It is necessary for the estimator to allow customers to quickly estimate the deduplication benefit on their primary data.
existing deduplication estimators are either not fast enough or not accurate enough.
Content-based Sample
- Theory Assume a hash function that generates a fingerprint for each data block. The proposed content-based sampling applies a modulo-based filter to all the block fingerprints of a data set.
A block fingerprint passes the filter and is added to the sample Mod == , is the filter divisor.
Idea: split the fingerprint space into partitions, and to use one of the partitions in the estimation.
The estimation of distinct block size in the whole data set: can also consider the case where the size of block is different.
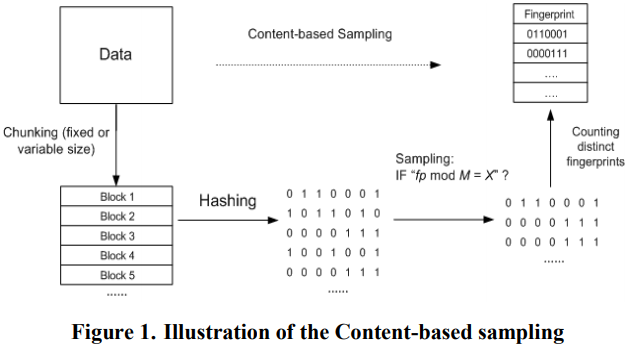
- How to set ? Define a accuracy notion, to prove how to choose under the given and .
Implementation and Evaluation
- Changing logging module: samples data blocks during the consistency point. (for update)
- Disk Scanner: sample existing blocks in the volume.
- All the sample will store in a fingerprint sample file (FPS).
- Estimation Operation: merges the sample from change logging to the FPS, and update the estimate accordingly.
- Experiment
- Accuracy
- Performance degradation: increase the rate of random access for counting module.
2. Strength (Contributions of the paper)
- this work provides a single-scan-pass method for estimating deduplication ratio in a large dataset, also, with statistically guaranteed accuracy.
- This work also consider to tackle the rapid change of dataset.
- It implements this technique in a real commercial storage system for real world dataset. It also verifies the impact of performance (less than a few percent).
3. Weakness (Limitations of the paper)
- Theory of proving the correctness bound of is not very clear, I cannot understand the rationale behind them.
4. Future Works
This paper provides a very simple sample method based on fingerprint, i.e., content-based, this is not very novel from my perspective. And this paper also presents the whole theory to support its idea. The insight is for large dataset, it is possible to estimate the deduplication ratio with sampling.