Cumulus: Filesystem Backup to the Cloud
| Venue | Category |
|---|---|
| FAST'09 | Backup system |
Cumulus: Filesystem Backup to the Cloud1. SummaryMotivation of this paperDesignImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some Insights (Future work)
1. Summary
Motivation of this paper
- Motivation Most existing cloud-based backup services implement integrated solutions that include backup-up specific software hosted on both the client and at the data center.
this approach allows greater storage and bandwidth efficiency, but reduce the portability (locking customers into a particular provider)
This paper intends to explore the thin cloud with a minimal interface (put, get, delete, list)
portable for any on-line storage services
- Main goal Cumulus tries to be network-friendly like rsync-basd tools, while using only a generic storage interface.
Design
- Storage server interface
- Get: input: the pathname, retrieve the contents of a file from the server
- Put: input: the pathname, store a complete file on the server
- List: get the names of files stored on the server
- Delete: remove the given file from the server
All of these operations operate on entire files.
the interface is simple enough that it can be implemented on top of any number of protocols.
- Write-one storage model the only way to modify a file in this narrow interface is to upload it again in full
a file is never modified after it is first stored, except to delete it to recover space. do not modify files in place.
- Storage segments
- Filesystem always contains many small files.
- When storing a snapshot, Cumulus often groups data from many smaller files together into large units. (segments)
- Amazon S3 encourages using files greater than in size.
Why? Provide additional privacy when encryption is used: Aggregation hide the size as well as contents of individual files.
- Snapshot format Snapshots logically consist of two parties:
- metadata log: lists all files backed up
- the data itself.
Both two parties are broken apart into blocks, and these objects are then packed together into segments.
Snapshot descriptors: the one piece of data in each snapshot not stored in a segment
include a timestamp and a pointer to the root object.
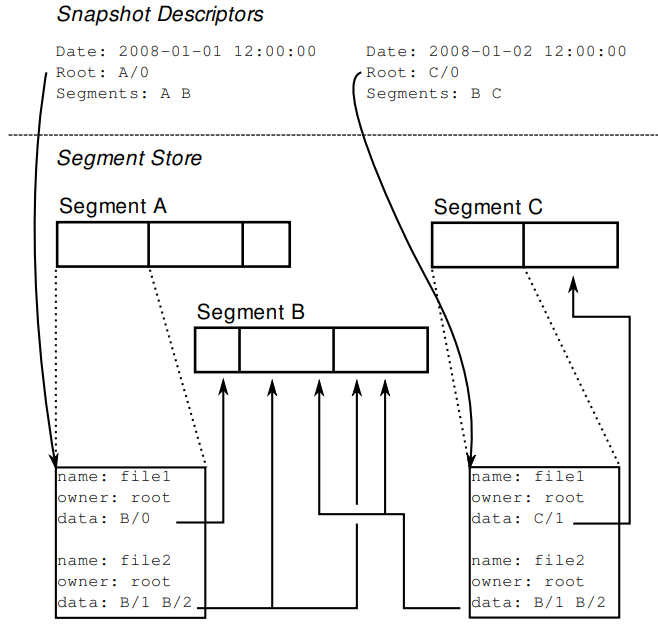 Starting with the root object stored in the snapshot descriptor and traversing all pointers found, a list of all segments required by the snapshot can be constructed.
Starting with the root object stored in the snapshot descriptor and traversing all pointers found, a list of all segments required by the snapshot can be constructed.
- Segment cleaning (GC)
- in-place cleaning: identifies segments with wasted space and rewrites the segments to keep just the needed data.
Cumulus: does not clean in place.
- The simplest policy: set a minimum segment utilization threshold. utilization: the fraction of bytes within the segment which are referenced by a current snapshot.
Restore
- Complete restore: extracts all files as they were on a given date
- Partial restore: recovers one or a small number of files.
Cumulus is primarily optimized for the complete restore.
Implementation and Evaluation
- Implementation Source code
3200 LoC c++ for core backup functionality. 1000 LoC python for restore, segment cleaning, and statistics gathering.
- Local client state each client stores on its local disk information about recent backups.
storing it locally reduces network bandwidth and improves access times. two parties: 1) a local copy of the metadata log, 2) SQLite database containing all other needed information,
Cumulus uses the local copy of the previous metadata log to quickly detect and skip over unchanged files based on modification time.
Database: keeps a record of recent snapshots and all segments and objects stored in them.
an index by content hash to support data deduplication.
- Segment cleaning Using Python controls cleaning.
when writing a snapshot, Cumulus records in the local database a summary of all segments used by the snapshot and the fraction of the data in each segment that is actually referenced.
- Segment filtering and storage Cumulus backup implementation is only capable of writing segments as uncompressed TAR files to local disk.
additional functionality is implemented by calling out to external scripts. using gzip to provide compression using boto library to interact with AWS
- Evaluation
- Trace workload: fileserver, user. (private dataset)
- Simulation and prototype evaluation
Prototype evaluation
- compare with Jungle Disk and Brackup.
- sub-file incrementals
comparison with rdiff (rsync-style)
- upload time
using boto Python library to interface with Amazon S3.
- restore time
2. Strength (Contributions of the paper)
- provide both simulation and experimental results of Cumulus performance, overhead and cost in trace-driven scenarios.
- Cumulus can leave the backup itself almost entirely opaque to the server.
make Cumulus portable to nearly any type of storage server.
3. Weakness (Limitations of the paper)
4. Some Insights (Future work)
- It also mentions Cumulus does not design deduplication between backups from different clients.
Since server-side deduplication is vulnerable to dictionary attacks to determine what data clients are storing, and storage accounting for billing purpose is more difficult.
- Cumulus also detects changes to files in the traces using a per-file hash.