DeepSketch: A New Machine Learning-Based Reference Search Technique for Post-Deduplication Delta Compression
| Venue | Category |
|---|---|
| FAST'22 | post-dedup |
DeepSketch: A New Machine Learning-Based Reference Search Technique for Post-Deduplication Delta Compression1. SummaryMotivation of this paperDeepSketchImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some Insights (Future work)
1. Summary
Motivation of this paper
Motivation
to maximize storage efficiency, existing post-deduplication delta-compression perform delta compression along with deduplication and lossless compression
existing approaches achieve significantly lower data-reduction ratios than the optimal due to their limited accuracy in identifying similar data blocks
super-feature data sketching (compared with brute-force searching (optimal))
- false-negative rate (FNR): cannot find a reference block
- false-positive rate (FPR): find a reference block different from the optimal
key question: how to find a good reference block that provides a high data-reduction ratio
DeepSketch
main idea: leverage the learning-to-hash method to achieve higher accuracy in reference search for delta compression
improve the data-reduction efficiency
envision DeepSketch's DNN is pre-trained before building or updating a DeepSketch-enabled system
similar to solving a nearest-neighbor search problem
- classification model + hash network model
main observation
high FNR of previous approaches
SFSketch is highly optimized to identify only very similar data
- fail to find a sufficiently good reference block (can still improve the data-reduction ratio)
two challenges of using DNN in DeepSketch (different from ML-related works)
lack of semantic information
- need to process a much wider range of data (unsupervised learning)
high dimensional space
- a large space for possible bit patterns
dynamic K-means clustering
address how to find appropriate initial parameters for clustering
dynamically refine the value of without any hints for initial parameters
- coarse-grained cluster + fine-grained cluster
- use the delta-compression ratio of two data blocks as the distance function
complexity
- space complexity: O(N)
- computation complexity: O(N^2)
neural-network training
transfer the learned knowledge of the classification model to a hash network model
- use GreedyHash
address the issue that data blocks are not uniformly distributed over clusters (may biased)
- adding data block randomly and slightly modified from ones in a cluster containing fewer blocks
reference selection
the traditional exact-matching-based search is not effective for the learning-to-hash model
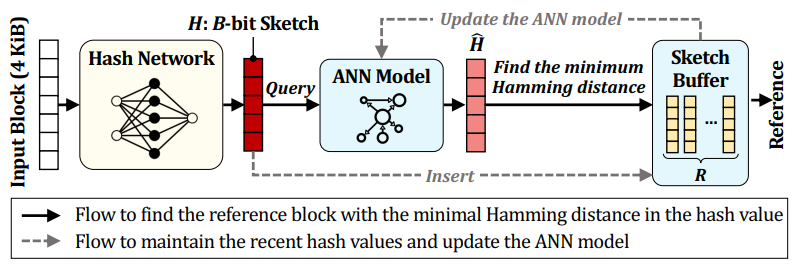
- use the approximate nearest neighbor search (ANN) technique (NGT library)
two sketch stores
- a ANN sketch store
- a most-recently-written block sketch store (avoid frequently updating the ANN model, improve the performance)
Implementation and Evaluation
Implementation
- a fingerprint store, a sketch store for delta compression
- sketch size: 128-bit
trace:
small traces: eleven block I/O traces
- 10% data for training and 90% data for evaluation
evaluation
baseline: Finesse
- all values are normalized to the data-reduction ratios of a baseline system that performs only deduplication and lossless compression in order (no delta compression)
overall data reduction
- data-reduction ratio
reference search pattern analysis
- to show the breakdown of why DeepSketch outperforms Finesse
combination with existing techniques (Finesse + DeepSketch)
- compared with optimal
impact of training data-set quality
- fraction of training data
overhead analysis
performance overhead: DeepSketch, Finesse and combination of DeepSketch + Finesse
- much lower than Finesse (44. 6% speed of Finesse)
- sketch generation, sketch retrieval, sketch store update, and deduplication, Xdelta compression, and LZ4 compression
memory overhead
2. Strength (Contributions of the paper)
the first machine learning-based reference search technique for post-deduplication delta compression
- an effective solution to generate data signatures for general binary data
address the the training issues for an extremely high-dimensional data set
3. Weakness (Limitations of the paper)
do not test DeepSketch in a large dataset
- the trace is too small
the improvement of DeepSketch is limited
- up to 33% of data-reduction ratio
it must target a scenario where data-reduction is paramount (e.g., backup system)
- otherwise, the performance overhead is unacceptable
4. Some Insights (Future work)
delta compression background
delta compression can achieve a high data-reduction ratio even for
- non-duplicate data: cannot benefit from data deduplication
- high-entropy data: lossless compression cannot efficiently handle
previous approaches can be collectively called locality-sensitive hash (LSH)
uncorrectable bit-error rate (UBER)
- collision rate is lower than the uncorrectable bit-error rate requirement of a disk
learning-to-hash method
trains a neural network (NN) to generate a hash value for a given input data block
- any two similar data blocks have similar hash values
- used in image retrieval
argument of the sketch index memory overhead
- the memory overhead for the sketch store is a common problem in all the sketch-based techniques