Combining Deduplication and Delta Compression to Achieve Low-Overhead Data Reduction on Backup Datasets
| Venue | Category |
|---|---|
| DCC'14 | Delta Compression |
Combining Deduplication and Delta Compression to Achieve Low-Overhead Data Reduction on Backup Datasets1. SummaryMotivation of this paperDAREImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some Insights (Future work)
1. Summary
Motivation of this paper
Motivation
- Effectively combines data deduplication and delta compression to achieve high reduction efficiency at low overhead.
DARE
main idea
- by considering any two data chunks to be similar if their respective adjacent data chunks are found to be duplicate
- further enhance the resemblance detection efficiency by an improved super-feature approach
workflow
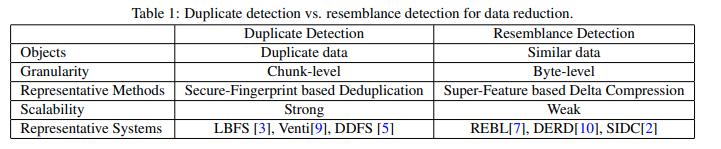
- duplicate detection: duplicate, non-duplicates
- DupAdj detection: similar, non-similar
- Improved super-feature approach: similar, non-similar
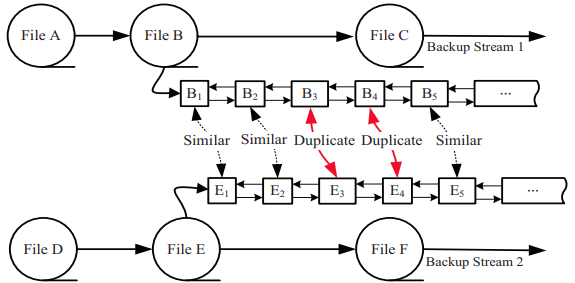
DupAdj: Duplicate-Adjacency based resemblance detection
insight: the modified chunks may be very similar to their previous versions in a backup system while unmodified chunks will remain duplicate and are easily identified by the deduplication process
DARE records the backup-stream locality of chunk sequence by a double-linked list.
- allows an efficient search of the duplicate-adjacent chunks for resemblance detection by traversing to prior or next chunks on the list
avoid the computation and indexing overhead for the conventional super-feature approach for resemblance detection
Improved super-feature based resemblance detection
Previous studies: use of 4 features to generate a super-feature to minimize false positives of resemblance detection
Insight in this work
- The large the number N of features used in obtaining a super-feature is, the less capable the super-feature is of resemblance detection
- The large the number M of super-feature is, the more resemblance can be detected and the more redundancy can be eliminated
an improved super-feature approach with fewer features per super-feature
- suggest that two features per super-feature appear to hit the "sweet spot" of resemblance detection
storage management
non-similar or delta chunks will be stored as containers into the disk
file recipe:
- mapping information among the duplicate chunks, resembling chunk, and non-similar chunks
Implementation and Evaluation
Implementation
- Rabin algorithm and SHA-1 for chunking and fingerprinting process
- a CDC sliding window size of 48 bytes to generate features and uses the Xdelta algorithm to compress the detected similar chunks
Evaluation
the impact of the number of features per SF and the number of SFs used in resemblance detection
scalability of DARE data reduction
restore performance
Intuitively, restore the resembling chunks by two reads
- one for the delta data, and the other for the base-chunk, then delta decode them
can cache more logical chunks than a deduplication-only system
- virtually enlarge the restore cache due to the delta compression
2. Strength (Contributions of the paper)
use the stream information in backup to find the similar chunks
- reduce the computation overhead
3. Weakness (Limitations of the paper)
the overhead performance of using both deduplication and delta compression is still very limited
- 50MB/s in RAID, 85MB/s in SSD
4. Some Insights (Future work)
Delta compression
detecting and compressing similar data missed by deduplication
remove redundancy among non-duplicate but very similar data files and chunks
- the data deduplication often fails to identify and eliminate
poor scalability
- require high computation and indexing overhead for resemblance detection
delta compression vs. deduplication