Even Data Placement for Load Balance in Reliable Distributed Deduplication Storage Systems
| Venue | Category |
|---|---|
| IWQoS'15 | Distributed Deduplication |
Even Data Placement for Load Balance in Reliable Distributed Deduplication Storage Systems1. SummaryMotivation of this paperEDPImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some Insights (Future work)
1. Summary
Motivation of this paper
This paper considers the scenario of distributed deduplication
- deduplication for storage efficiency
- erasure coding for reliability
It targets the problem of load balance in the above scenario
- read balance
- storage balance
Motivation Conventional data placement cannot simultaneously achieve both read balance and storage balance objectives.
the trade-off between read balance and storage balance.
Solve this problem by formulates a combinatorial optimization problem..
Even Data Placement (EDP) algorithm
EDP
- Root cause: deduplication causes duplicate data chunks to refer to existing identical data chunks that a re scattered across different nodes in an unpredictable way.
file chunks may be clustered in a small number of nodes. poor read performance.
- Integration (Deduplication + Erasure Coding)
- apply deduplication to remove duplicate chunks
- divide data into non-overlapping groups of unique chunks (as a stripe), then encode the data chunks to form additional parity chunks.
padding: when use variable-size chunking. (only store the non-padded chunks)
- Baseline policy
- round-robin fashion: the number of storage nodes is equal to the erasure coding stripe size.
with deduplication: inherently leads to uneven data distribution. breaking the connection between read balance and storage balance. (parallel I/O accesses)
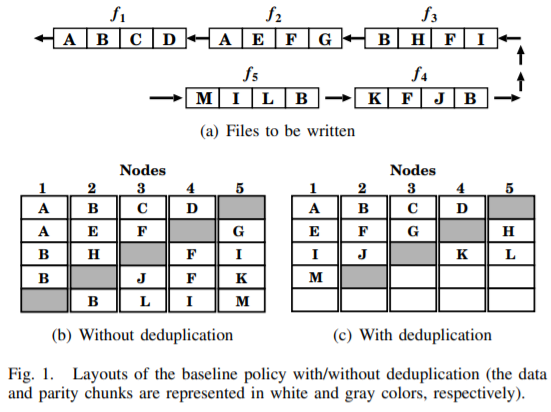
- Problem Model
- Per-batch basis Only consider the how to place the unique chunks to maximally achieve balanced read.
minimize the sum of the read balance gaps for all files. has a huge solution space for this optimization problem.
- Heterogeneity Awareness Modern distributed storage systems are often composed of heterogeneous nodes , so the read latencies of data chunks differ across nodes.
introducing a weight for each node .
Main Algorithm (based on greedy algorithm)
- Goal: aim to efficiently identify a near-optimal data placement solution.
- Two steps: Distribute and Swap.
Swap: attempts to swap the chunk positions of different file pairs to see if the summation of the read balance gaps can be further reduced.
Some extensions
- Heterogeneity environment
- Variable-size chunking: consider the number of bytes rather than number of chunks.
System Architecture
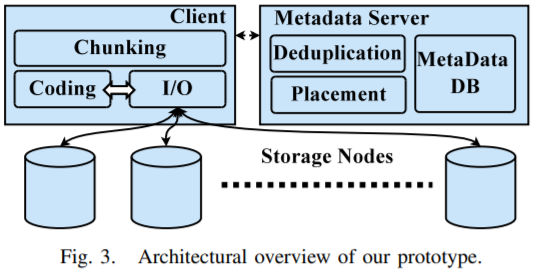
Metadata server runs the data placement policy, then responds to the client with the list of unique chunks and how they placed across nodes. Clients then applies erasure coding to the unique chunks, and writes the encoded chunks to different nodes in parallel. Metadata server: maintain metadata in key-value databases and implement them using Kyoto Cabinet library.
Implementation and Evaluation
Evaluation
- Dataset: FSL-home, Linux kernel source code (unpacked), Linux kernel source code (tarball file)
- filter small files of size less than 16KB
Simulation experiments
- Effectiveness of EDP
- Impact of erasure coding
- Impact of heterogeneity
varying I/O bandwidth across nodes
- Testbed experiments
- the normalized read latency
- Impact of chunking schemes: fixed-size and variable-size chunking schemes
- Read latency distribution:
- Computational overhead: varying the number of files in each batch.
2. Strength (Contributions of the paper)
- formulating an optimization problem for read balance and storage balance.
extend this optimization problem to heterogeneous environments. EDP algorithm, greedy algorithm.
- implement a distributed storage system prototype
combining deduplication and erasure coding extensive simulation and testbed experiments under real-world workloads.
3. Weakness (Limitations of the paper)
- The overhead of this algorithm is high. Although EDP is in polynomial time, it needs to buffer each batch of unique chunks and wait the schedule result. I deem it would harm the performance dramatically.
near-optimal?
4. Some Insights (Future work)
- this paper assumes that the network transmission is the bottleneck, so it needs to leverage the I/O parallel to guarantee the performance. If this assumption cannot keep, this problem may because unnecessary.
- A trade-off between read balance and storage balance.