Finesse: Fine-Grained Feature Locality based Fast Resemblance Detection for Post-Deduplication Delta Compression
| Venue | Category |
|---|---|
| FAST'19 | Similarity Deduplication |
Finesse: Fine-Grained Feature Locality based Fast Resemblance Detection for Post-Deduplication Delta Compression1. SummaryMotivation of this paperFinesseImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Future Works
1. Summary
Motivation of this paper
The drawback in current deduplication:
it cannot remove redundant data among non-duplicate but very similar chunks
To handle this issue, a way is to adopt delta compression whose main idea is exeucting resemblance detection to detect delta compression candidate, and just storing the difference (delta) and base chunk.
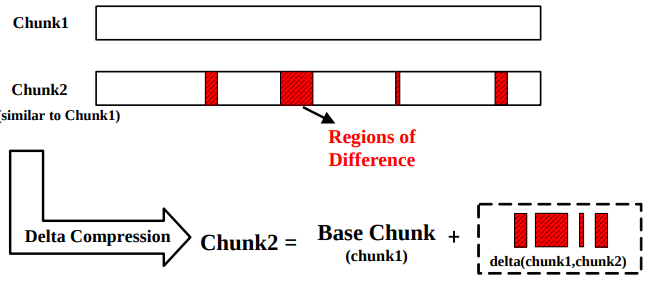 Issue: Current similarity detection algorithm is based on N-transform Super-Feature which needs to extract a fixed number of features from a chunk by requiring N linear transformations for each fingerprint to generate N-dimensional hash value sets.
Issue: Current similarity detection algorithm is based on N-transform Super-Feature which needs to extract a fixed number of features from a chunk by requiring N linear transformations for each fingerprint to generate N-dimensional hash value sets.
this process is time-consumed and compute-intensive because it requires too many linear transformations when generating super features
Finesse
Based on a key observation of fine-grained locality among similar chunks (feature locality)
the corresponding subchunk of chunks and their features also appear in same order among the similar chunks with a very high probability.
- Key Question How to fast detect high similarity chunk?
- Basic Idea computing the similarity by first
- dividing each chunk into several subchunks (to get N features
N equal-sized subchunks) - quickly computing features from each subchunk
- finally grouping these features into SFs.
By this way, it can eliminate the linear transformations and thus simplify the feature computation.
Point of support: Most of the corresponding subchunk pairs in the detected similar chunks have the same features in six datasets.
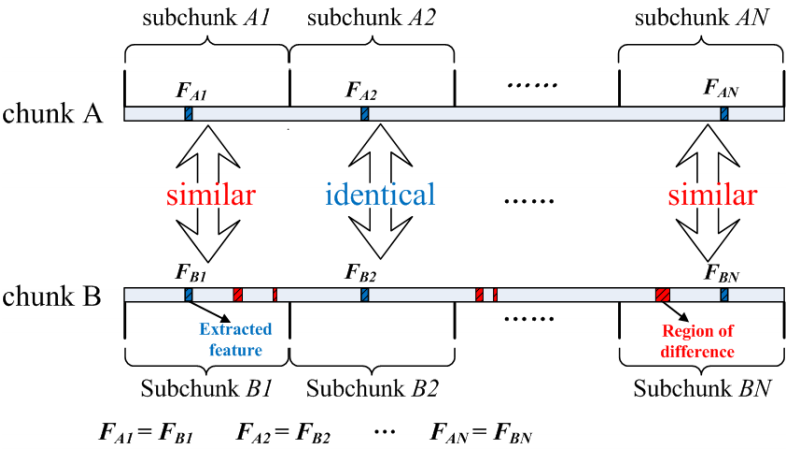
- Feature extraction divide the chunk into several sub-chunks with fixed size, get the maximum rabin fingerprint value.
- Feature grouping Principle: features in an SF should be extracted from the subchunks distributed uniformly across the chunk.
Can be implemented simply by sorting
the whole workflow
- deduplication: an in-memory SHA-1 fingerprint table
- resemblance detection: Finesse and N-transform
- base chunk reading: use a base chunk cache with LRU and a size of 400MiB to reduce base chunk I/Os
- delta encoding: use the classic Xdelta
Implementation and Evaluation
Implementation:
implement delta compression in an open-source deduplication prototype system (Destor)
deltra encoding
Evaluation:
- Delta Compression Ratio (DCR): overall space saving
- Delta Compression Efficiency (DCE): focus on teh detected resembling chunks
- Similarity Computing Speed
- System Throughput
2. Strength (Contributions of the paper)
- This paper tries to reduce the computation overhead of resemblance detection by using the feature loaclity in subchunks. It provides sufficient experiment observation to support its idea which makes it more concrete.
3. Weakness (Limitations of the paper)
- One key limitation in this paper is it can just detect the similar chunks with same size. How to handle the case when two high similarity chunks with different sizes can be considered.
4. Future Works
I think this paper is related to how to measure the chunk similarity between two given chunks. However, it still cannot quantify the similarity between two chunks which limits to further optimize the delta compression. One thing can be considered is to design a model to quantify the similarity between two given chunks.