Frequency Based Chunking for Data De-Duplication
| Venue | Category |
|---|---|
| MASCOTS'10 | Deduplication Chunking |
Frequency Based Chunking for Data De-Duplication 1. SummaryMotivation of this paperFrequency Based ChunkingImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Future Works
1. Summary
Motivation of this paper
This paper proposes a frequency based chunking algorithm, which utilizes the chunk frequency information in the data stream to enhance the data deduplication gain.
Especially when the metadata overhead is taken into consideration.
The popular baseline CDC algorithm employs a deterministic distinct sampling technique to determine the chunk boundaries based on the data content.
Drawback of CDC: Although CDC is scalable and efficient, content defined chunking is essentially a random chunking algorithm.
does not guarantee the appeared frequency of the resultant chunks may not be optimal for data dedup purpose.
The only option for the CDC algorithm is to reduce the average chunk size
when the average chunk size is below a certain value, the gain in the reduction of redundant chunks is diminished by the increase of the metadata cost.
Frequency Based Chunking
Main idea: after a coarse grained CDC algorithm, they then performs a second level (fine-grained) chunking by identifying the chunks with a frequency greater than a predefined threshold.
this method requires a strong assumption on the knowledge of the individual chunk frequency. two steps: chunk frequency estimation + chunking
- Data dedup gain Define the amount of duplicated chunks removed and the cost of the metadata. ,
here, is the number of times a unique chunk appears in the stream.
is the minimal length of a chunk pointer that points to each unique chunk. 20 is the 20-byte SHA-1 hash.
- Frequency Estimation In this paper, it adopts the concept of parallel stream filter and designs a special parallel bloom filter to identify high-frequency chunks and to obtain their frequency estimates.
How to reduce the oveahead of estimation? This algorithm may only require the knowledge of high-frequency chunk candidates.
One interesting observation is that a majority of the chunk candidates are of low frequencies.
Based on this idea, this paper applies a filtering process to eliminate as many low-frequency chunks as possible.
reserve resource to obtain an accurate frequency estimate for the high-frequency chunks.
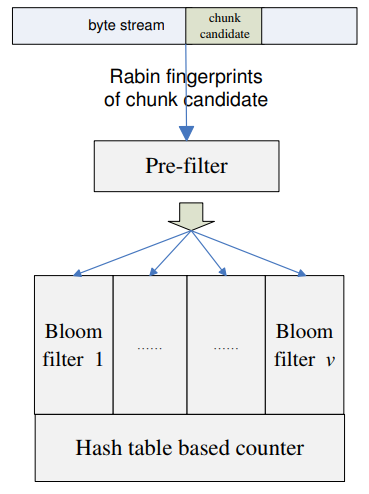
- Prefiltering require only one XOR operation for filtering decision per chunk candidate it observes.
has a parameter to control the sample rate for example, , makes a chunk candidate pass if its Rabin's fingerprint value modulo 32 == 1
- Parallel filtering After prefiltering, it then starts to check the appearance of a given in all bloom filters.
If it can find this chunk in each of the bloom filters, then it lets this chunk pass through the parallel filter and start to count its frequency. Otherwise, it records the chunk in one of the bloom filters randomly.
Without considering the false positive caused by bloom filters, only chunk candidates with frequency greater than can possibly pass the parallel filtering process.
Due to the efficiency of the bloom filter data structure, it only consumes a small amount of memory, in this way they can filter out majority of the low frequency chunk candidates with small amount of resource.
It mentions that although there is a rich literature for detecting high frequency items in a data stream.
However, for this problem, the threshold for high frequency chunks is usually as low as 15. The classical heavy hitter detection algorithms do not scale under such a low threshold.
- Two-stage chunking Main idea: combining the coarse-grained CDC chunking with fine-grained frequency based chunking.
Implementation and Evaluation
- Evaluation Datasets: three empirical datasets
two datasets (Linux and Nytimes): data streams exhibit high degree of redundancy one dataset (Mailbox): dataset with low detectable redundancy
Evaluation Criteria:
Duplicate Elimination Ratio Average Chunk Size
2. Strength (Contributions of the paper)
- the FBC algorithm persistently outperforms the CDC algorithm in terms of
achieving a better dedup gain producing much less number of chunks
- This paper advances the notion of data dudep gain to compare different chunking algorithms in a realistic scenario. (Dedup saving and metadata overhead)
- propose a novel frequency based chunking algorithm
considers the frequency information of data segments during chunking process.
- design a statistical chunk frequency estimation algorithm.
with small memory footprint
3. Weakness (Limitations of the paper)
- The writing of this paper is not very clear.
- For this approach, it needs an extra pass on the dataset to obtain frequency information
it needs to design a one-pass algorithm which conducts the frequency estimation and the chunking process simultaneously. An intuitive idea: tracking top k frequency segments instead of tracking all segments with frequency greater than a certain threshold.
4. Future Works
- In this paper, one thing I can use is the idea that using a filter to reduce the memory overhead in hashtable. (how about use the sketch as a filter?)
- This paper considers a fix-sized chunk to be frequent if its frequency no less than a pre-defined threshold
this threshold is determined based on domain knowledge on the datasets.