Improving the Restore Performance via Physical-Locality Middleware for Backup Systems
| Venue | Category |
|---|---|
| Middleware'20 | Deduplication Restore |
Improving the Restore Performance via Physical-Locality Middleware for Backup Systems1. SummaryMotivation of this paperHiDeStoreImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some Insights (Future work)
1. Summary
Motivation of this paper
Motivation
Deduplication suffers from low restore performance, since the chunks are heavily
fragmentedhave to read a large number of containers to obtain all chunks
- incurring lots of expensive I/Os to the persistent storage
Limitations of existing work
caching scheme
fail to alleviate the fragmentation problem since the chunks are stored into more containers
- as the backup data increase
rewriting scheme
- the deduplication ratio decreases due the existence of duplicate chunks
Open-source
HiDeStore
Main insight
identify the chunks that are more likely to be shared by the subsequent backup versions
- e.g., hot chunks
- store those hot chunks together to enhance the physical locality for the new backup versions
other chunks (i.e., have the low probability to be shared by the new backup versions) are stored in the containers as the traditional deduplication schemes
- e.g., cold chunks
Trace analysis
Linux kernal, gcc, fslhomes, and macos
- heuristic experiment is conducted on
Destor
- heuristic experiment is conducted on
version tag
indicates the backup version recently containing the chunk
- the chunk that are not contained in the new backup versions will always maintain the old version tags
Finding
the chunk not appearing in the current backup version have a low probability to appear in the subsequent backup versions
- reason: the new backup version is generated via upgrading the old ones
Key idea:
a reverse online deduplication process
- the fragmented chunks are generated in the old backup versions rather than the new ones
only search the chunks with high probability to be deduplicated with coming chunks
- i.e., the chunks in previous backup versions
classify and respectively store the hot and cold chunks
- groups the chunks of new backup version closely
Fingerprint cache with double hash
- only search the fingerprint cache without further searching the full index table on disks
- the fingerprint cache mainly contains the chunks with a high duplicate probability
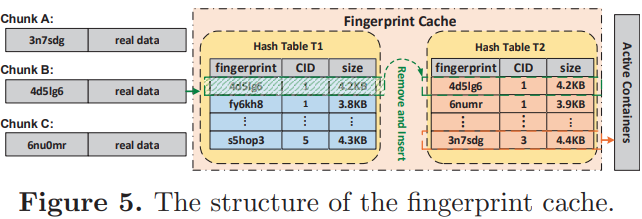
T1: contains the metadata of the chunks in previous version
T2: used to contain the chunks of current version
After deduplication against current version, the chunks not appearing in current version are left in T1
- i.e., the cold chunks
- move the cold chunks from active containers to archival containers after deduplicating current version and updates the recipes
index overhead
the sizes of T1 and T2 are bounded and hardly full
the total size of hash table is limited to the
size of one (or two) backup versionsachieves almost the same deduplication ratio like the exact deduplication
still has the extre storage overhead
Chunk filter to separate chunks
Separately stores the hot and cold chunks by changing the writing paths of the chunks
Container structure
- metadata section: container ID, data size,
hash table(key: fingerprint, value: a pointer to the corresponding chunks) - data section: the real data of the contained chunks
- metadata section: container ID, data size,
the hot chunks are temporarily stored in active containers during the deduplication phase
need to compact the active containers to enhance the physical locality, directly merge sparse containers in to the same container without considering the order
- since move cold chunks to the archival containers
Update recipes
all recipes form a chain
need to read multiple recipes to find the concrete location for each chunk when restoring the old backups
- incur
high latency
- incur
need to update the recipes when moving the cold chunks
- since the locations of the chunks are modified
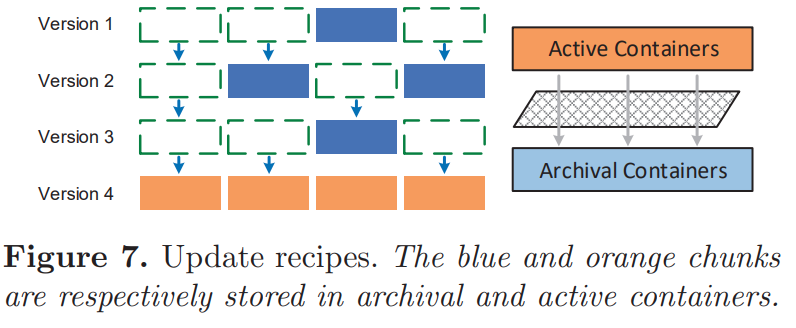
Restore phase
the recipe contains three types of contain ID (CID)
- positive CID: archival container
- negative CID: the backup version
- 0: indicates the active container
Garbage collection
HiDeStore has stored the chunks belonging to different backup versions separately
- without the needs for expensive chunk detection and
Implementation and Evaluation
Evaluation
- Restore baseline: capping, ALACC, and FBW
- Deduplication performance baseline: DDFS, Sparse Index, and Silo
- Trace: kernel, gcc, fslhomes and macos
Deduplication ratio
- HiDeStore achieves almost the same deduplication ratio as DDFS
Deduplication throughput
Destor evaluates the number of the request for the full index table
is not absolute throughput(simulate the requests to disks)
HiDeStore only needs to search the fingerprint cache without the needs to frequently access the full index table on the disk
- use prefetching to load the index into the fingerprint cache in advance
Space consumption for index table
it does not need extra space to store the indexes, since HiDeStore deduplicates one backup version against its previous one
- the fingerprint indexes of all chunks in previous backup version have been stored in the recipe
Restore performance
- metric: the mean data size that is restored per container
HiDeStore overhead
- updating recipes
- moving the chunks from active containers to archival containers
The deletion
- HiDeStore does not need any efforts for GC
2. Strength (Contributions of the paper)
propose the idea to separately store the hot chunks and cold chunks
- for each backup
3. Weakness (Limitations of the paper)
this work only consider the case for a single client backup
- the assumption is weak from my view, how about multiple clients' backups
4. Some Insights (Future work)
recipe background
the data structure of the recipe is a chunk list, and each item contains:
- a chunk fingerprint (20 bytes)
- the ID of the container (4 bytes)
- the offset in the container (4 bytes)
assemble the data stream in memory in the chunk-by-chunk manner
Workload dependence
It can simply
trace the chunk distributionamong versions and determine whether to use the proposed scheme- the overhead is low, since it only needs to trace the metadata of the chunks