Improving Restore Speed for Backup Systems that Use Inline Chunk-Based Deduplication
| Venue | Category |
|---|---|
| FAST'13 | Deduplication Restore |
Improving Restore Speed for Backup Systems that Use Inline Chunk-Based Deduplication1. SummaryMotivation of this paperMethod NameImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Future Works
1. Summary
Motivation of this paper
Restore speed in such systems often suffers due to chunk fragmentation.
Modern disks' relatively poor random I/O performance compared to sequential I/O, fragmentation greatly hurts restore performance.
Due to chunk sharing between backups, it is not possible in general to find a chunk layout that reduces the fragmentation.
Rearranging chunks can also be expensive
Chunk fragmentation and restore performance gets worse as time goes by, and affects the recent backups the most.
slowdowns of over three months for one and over two years for the other.
This paper investigates
- how fragmentation and restore speed behave over time and under different cache size?
- two approaches to improve restore speed in these deduplication system.
Method Name
- Background
- A backup (stream): a sequence of chunks generated by a chunking algorithm.
- Chunk container: store chunks, one container per incoming stream.
- Open container (4MB): the container that is used for storing new chunks from that stream.
- For RAID or recipe reference indirection, it is more efficient to blindly read the entire container even when we need only on chunk.
- Simulation This paper does the simulation under a default simple n-slot LRU container cache
hold n chunk containers at a time and take container size space. Measurement factor: the mean number of containers read per of backup restored for the backups of a long term data set. Proof: reading containers is the dominant restore cost.
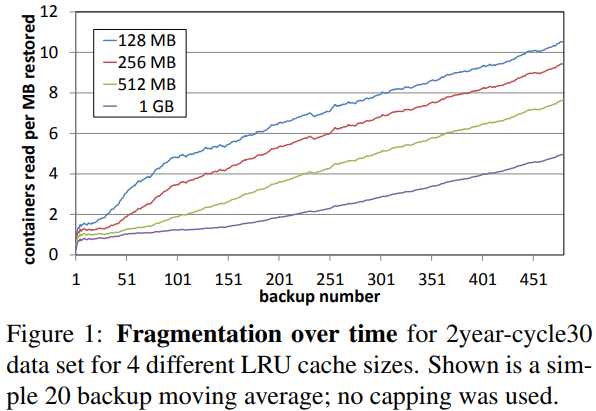
- Measuring restore speed This paper introduces a new restore speed proxy: speed factor. . This can estimate of absolute system performance via:
- raw I/O performance
- the container size
- Container Capping Main idea: limit how many containers need to be read at restore time for each section of the backup.
Capping trades off deduplication for faster restore speed
- In order to use fewer old containers, it has to give up deduplication
- instead of using a reference to an existing chunk copy in an old container, it will store a duplicate copy of that chunk in an open container and point to that copy.
Step:
- Divide the backup stream into several segments (default 20MB)
- The capping requires an extra segment-sized buffer in RAM for each stream being ingested.
- Choose a threshold T based on the information about which containers contain which chunks of the segment.
- Rank order the containers by how many chunks of the segment they contain, breaking ties in favor of more recent containers, and choose the top T containers which contain the most chunks.
- Append any "new" chunks to the open containers.
This process guarantees that the recipe for each segments refers to at most T old containers plus a little number of new containers containing "new" chunks.
- Forward Assembly Area Main Idea: future knowledge of accessses can be exploited to improve both caching and prefetching.
In deduplicated backup streams, two points different virtual memory paging:
- the effective unit of I/O is an entire chunk container (4MB), whereas the unit of the use is a much smaller variable-size chunk.
- at the time of starting the restore: it can have the prefect knowledge of the exact sequency of chunks that will be used thanks to the backup's recipe.
Main step: Page in chunk containers to a single buffer but cache chunks rather than containers to avoid keeping around chunks that will never be used.
consult the next part of recipe to make better decisions about what chunks from the paged-in containers to retain.
Goal: need load each container only once per range (M-byte slice) and do not keep around chunks that will not be needed during this range
This method can also combine with ring buffer to further improve the efficiency of memory usage.
Implementation and Evaluation
- Implementation Modified one of them deduplication simulators, and apply it two primary data sets under various caching strategies, and the effects of capping and container size.
- deduplication performance
- fragmentation
- restore performance
Details: 9000 C++ program
- full chunk index: map the hashes of stored chunks to the chunk container
- chunk container size: 4MB
- mainly focus on deduplication ratio and speed factor
2. Strength (Contributions of the paper)
- This paper shows that it is possible to give up a relatively small percentage of deduplication in practice and get quite substantial speedups.
- By using capping, it truly can reduce fragmentation.
3. Weakness (Limitations of the paper)
- Given a workload, maybe it is hard to estimate the degree of trade-off between speedup factors and deduplication ratio.
4. Future Works
- the idea of container capping is to achieve substantial speedups while giving up only a small amount of deduplication.
- This paper also mentions that for deduplication restore, it should use all available RAM for restoring a system for a single large forward assembly area and associated buffers.
Unless deduplication is at a great premium, at least a small amount of capping should be employed.
- Adaptiving capping
- Given a workload, how to measure the fragmentation level at different scale?