InftyDedup: Scalable and Cost-Effective Cloud Tiering with Deduplication
| Venue | Category |
|---|---|
| FAST'23 | dedup system design |
InftyDedup: Scalable and Cost-Effective Cloud Tiering with Deduplication1. SummaryMotivation of this paperInftyDedupImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some Insights (Future work)
1. Summary
Motivation of this paper
problems
state-of-the-art cloud storage systems do not offer deduplication as a core functionality for their clients
need new deduplication algorithms tailored for cloud tiering
a large variety of available cloud storage service types
differing in pricing models
trade-off: a decreased per-byte monthly storage fee --> the cost of data retrieval and the minimal data storage period are increased
algorithms have to be devised to decide what type of service to use for which data
InftyDedup
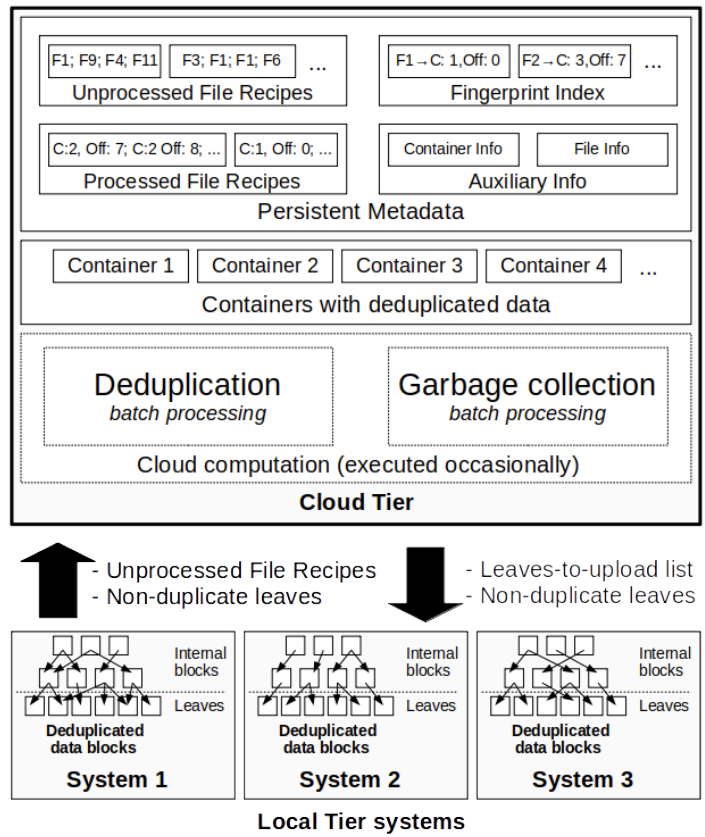
cloud cost considerations (key observation)
modern architecture of inline deduplication often keep the fingerprint index on SSDs
relying on a random-read-intensive fingerprint index is not negligibly cheap in the cloud environment
dynamically scaling resources between zero and hundreds of servers, processing the fingerprint index sequentially with a batch job
more cost-effective than keeping the fingerprint index online 24/7
all metadata required for deduplication must be stored and processed outside the local tier
data movement between the tiers should be minimal --> non-duplicate data must be uploaded to the cloud tier
batch processing is preferred over streaming processing
once a day
a costly deduplication query with each write brings few benefits in practice
data and metadata in cloud
keep in cloud object storage
containers
unprocessed file recipes (UFR)
the fingerprint of each block
processed file recipes (PFR)
fp, a cloud address of the block it references
fingerprint index
bucketed: each bucket is small enough to fit into server memory
enable optimization of distributed fingerprint index
communication between tiers
each selected file, the local tier system generates a UFR --> as an input to batch deduplication
in return, a blocks-to-upload list: comprise unique blocks
batch deduplication
step-1: UFR processing
Fingerprint index and UFRs are bucketed based on fingerprints
buckets are distributed across multiple servers
step-2: container generation
step-3: PFR update
when the block location is finally known for both new and old blocks
step-4: block upload
batch GC: ensure scalability
step-1: file removal
find blocks that are still referenced by the least one file
step-2: container verification
check how many blocks in each container are live
step-3: update metadata
update the address in fingerprint index and PFRs
step-4: rewrite the container
GC strategy
reclaim only empty containers
with no additional cost --> does not remove containers in which only a fraction of data has been deleted
reclaim containers if the rewrite pays for itself after T days
picking the value of parameters is non-trivial
reclaim containers based on file expiration dates
expiration date provided by the local tier systems
file restore
for blocks available locally, the download from the cloud can be omitted
cold storage utilization (mixing storage type)
write blocks to more than one storage type
select whether a block should be stored in hot or cold cloud storage
current expiration date
rough, expected frequency of file restore
BatchGC can move a block from one type of storage to another
Implementation and Evaluation
evaluation
AWS: m5d.xlarge instances
workload
backup file (51 GiB), synthetic data
FSL traces
performance
batch deduplication && batch GC
initial backup + incremental backup
208 TiB -> 1.66 PiB
strategies evaluation
GC strategies evaluation
storage type selection evaluation
different public cloud
with the pricing model of Google Cloud and Microsoft Azure
2. Strength (Contributions of the paper)
maximize scalability by utilizing cloud services not only for storage but also for computation
deduplicate data using the cloud infrastructure
batching algorithm
an algorithm for decreasing the financial cost of storing deduplicated data in the cloud tier
move deduplicated data chunks between cloud services dedicated to hot and cold storage
based on deduplication reference counts and info provided by system admin
3. Weakness (Limitations of the paper)
selecting GC parameters is non-trivial
how to select the hot and cold storage type is hard to follow
4. Some Insights (Future work)
cloud tiering
moving selected data from local on-premise storage to the cloud
colder data, e.g., older backups and archives
deduplication in cloud tiering
the data kept in the cloud tier are ultimately deduplicated
current research in cloud tiering deduplication
heavily rely on and are implemented mainly in the local tier
the actual scalability is severely limited (offered by the local tier)
deduplication between different local tier systems is not supported for data stored in the cloud
lifecycle of backups
recent data is kept as closely as possible to the infrastructure
older version of backups need to be stored for weeks, months, or even years
backups are often moved to cheaper storage after a specific time (cloud)
cloud storage
prices: cold archival object stores << block devices
moving terabytes to the cloud can take up days
cloud computing
spot instance
virtual machines with a discounted price of up to 90%
can be interrupted by a cloud provider at any moment
can have their local storage, cheaper than network-attached drives
limited durability: if the machine is destroyed or fails --> data are lost