LIPA: A Learning-based Indexing and Prefetching Approach for Data Deduplication
| Venue | Category |
|---|---|
| MSST'19 | Deduplication Index |
LIPA: A Learning-based Indexing and Prefetching Approach for Data Deduplication1. SummaryMotivation of this paperLearning-based Indexing Prefetching Approach (LIPA)Implementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Future Works
1. Summary
Motivation of this paper
This paper uses the reinforcement learning framework to build an adaptive indexing structure.
to solve the chunk-lookup disk bottleneck problem for large-scale
Current methods:
- a full chunk
- a sampled chunk index drawback: hard to fit in RAM and sampled chunk index directly affects the deduplication ratio dependent on the sampling ratio.
Problem: how to build an efficient fingerprint indexing to help identify duplicate data chunks?
chunk-lookup disk bottleneck problem
Learning-based Indexing Prefetching Approach (LIPA)
Goal: propose a simple reinforcement learning method to learn how to prefetch a segment dynamically.
a trial-and-error prefectching and then gives a delayed reward during the data stream evolution.
- Main idea Explore locality in context of data streams:
An incoming segment may share the same feature with previous neighboring segments
This paper trains the locality relationship and deduplicate each incoming segment against only a few of its previous segments.
By using reinforcement learning mythology,
it aims to identify the most similar segment (champion) for an incoming segment (temporal locality) then prefetch several successive segments (followers) by exploiting spatial locality.
- Segment similarity say two segments are similar if they share a number of the same chunks.
- Reinforcement learning
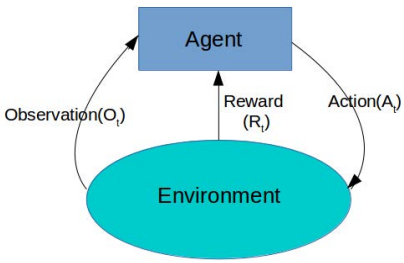 In this paper, it uses K-armed contextual bandit, the goal of the agent is to obtain rewards as much as possible in the long term.
In this paper, it uses K-armed contextual bandit, the goal of the agent is to obtain rewards as much as possible in the long term. - The whole workflow
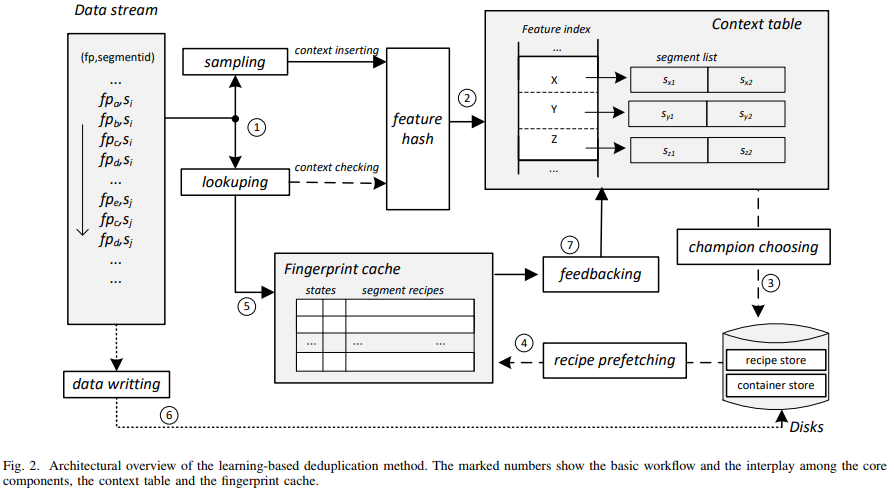 the deduplication relies on the interaction between of the context table and the fingerprint table (fingerprint cache)
the deduplication relies on the interaction between of the context table and the fingerprint table (fingerprint cache)
- Feature sampling sample no larger than for a segment sized of , sample rate: .
- Champion choosing The context table usually keeps a score for each segment which reflects its contribution to deduplication in the past time.
choose a segment with the higher score
- Reward feedback During the period of a champion in cache, it adds up all lookup hits until it is evicted from cache and then feedback the reward and update the corresponding score in the context table.
a reward value: the count of the lookup hits of the segment. once update or incremental update
Implementation and Evaluation
- Implementation Based on Destor: each phase corresponds to a thread.
chunking, hashing, indexing, storing
- Evaluation
- Dataset
- Linux Kernel archival: 155 versions
- Vmdk: pre-made VM disk images for VMware's Virtual Appliance Market place.
- Fslhome: 9 users in 14 days from Sep. 16th to 30th in 2011
- FSL MacOS
- Deduplication ratio
- RAM usage memory overhead for the fingerprint index lookup.
- Data throughput
2. Strength (Contributions of the paper)
- the main contribution of this work is that it proposes a new deduplication framework based on reinforcement learning for data deduplication.
3. Weakness (Limitations of the paper)
- the rationale behind this work is still vague, it should explains
segment with higher score higher lookup hits should be cached? it just shows this via experiments instead of theoretical analysis
4. Future Works
- This work mentions the point that here lacks an adaptive feedback mechanism to adjust the mapping relationship to reflect the dynamics of incoming data streams.
refer from MSST'16: even similar users behave quite differently, which should be accounted for in future deduplication systems.
- The key reinforcement learning algorithm is based on K-armed bandit.
a very general learning framework for prefetching
- This paper mentions that it is important to find a better balance between
exploitation by selecting a segment known to be useful. exploration by selecting a segment whose usefulness is unknown but which might provide a bigger reward and thus expand the known space.
- This work mentions that it can be strengthen LIPA to capture the regular and irregular patterns by using a number of upper-level access hints and file attributes.