Combining Buffered I/O and Direct I/O in Distributed File Systems
| Venue | Category |
|---|---|
| FAST'24 | HPC Storage |
Combining Buffered I/O and Direct I/O in Distributed File Systems1. SummaryMotivation of this paperLustre: BIO, DIO switchesImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some Insights (Future work)
1. Summary
Motivation of this paper
motivation
HPC applications still mostly rely on buffered I/O
even if direct I/O could perform better in a given situation
Linux's default I/O mode is buffered I/O
often unclear which I/O mode to use
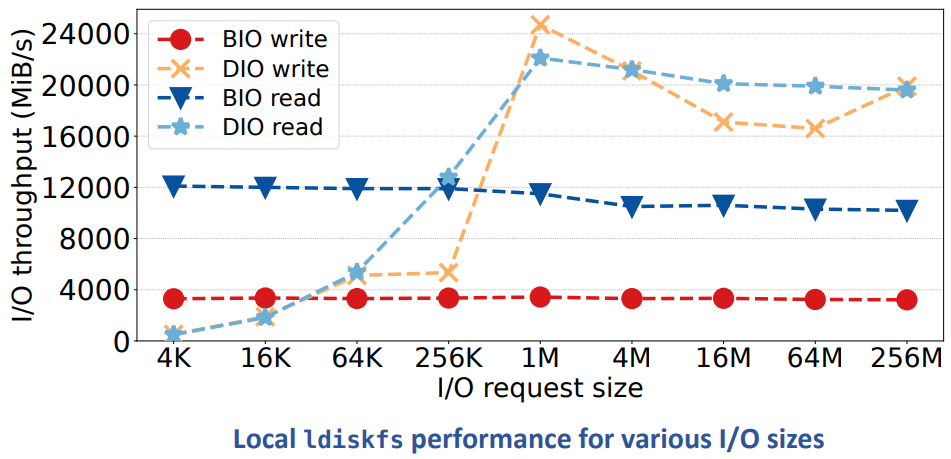
performance wall for buffered I/O
available memory for caching and page cache overhead
independent of available storage bandwidth or number of the attached storage system
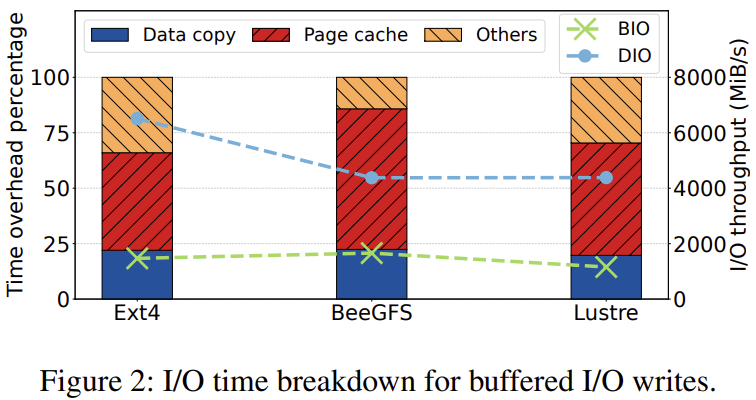
various challenges hinder higher direct I/O adoption
users tend to use the familiar I/O mode
alignment constraints
Lustre: BIO, DIO switches
present a new transparent approach to dynamically switches to each I/O mode
based on the I/O size, file local contention, memory constraints
AutoIO
automatically selects the I/O mode on the client side
small I/O threshold (32KiB), large I/O threshold (2MiB)
between: use BIO by default
limited the number of cached pages of a file to 1GiB by default

does not switch to buffered I/O when a user opens a file with O_DIRECT flag
adaptive server-side locking for direct I/O
non page-aligned extent
I/O regions do not overlay
still lock contention --> client must obtain page-aligned extent locks --> many ping-pong lock callbacks
server-side locking for direct I/O
clients send I/O requests to the server, which acquires the DLM lock on the client's behalf
saving lock round-trip traffic
file is under lock contention --> benefits of direct I/O shift towards smaller I/O sizes
detect lock contention
sliding window counter
at least 16 conflicting lock requests are seen over a sliding window of 4 seconds
server reports to the client --> switch to DIO
server-side adaptive write-back and write-through
for large I/O requests
each I/O service thread uses a pre-allocated buffer (4MiB ~ max bulk RPC size)
avoid the overhead of kernel page cache
immediately submitted to storage --> avoid memory contention
does not fully utilize the disk bandwidth for small I/O requests
for latency-sensitive I/O requests
switch to BIO via page cache (e.g., < 64KiB IO)
cross-file batching for buffered writes
many small writes across many small files
batch dirty pages of multiple files into one large bulk RPC
improve network efficiency
configurable threshold
distinguish whether a file is small enough to benefit
client maintain a small-file list < threshold
monitor their dirty pages
unaligned direct I/O
not all applications can align their I/O
underly file system should handle misaligned I/O in the kernel
implement a buffering scheme in the Lustre client
create an aligned buffer in the kernel --> read outside data in the user buffer --> then do DIO
require additional memory allocation and date copying
still outperforms buffered I/O, for large I/O sizes
less than 20% of its time on allocating memory and copying data
delayed block allocation
reduce fragmentation
enable delayed allocation in write-back mode on the server
merge small or non-contiguous I/O requests into large, contiguous I/O requests
allocate blocks at flush time
leverage extent status trees
track the status of delayed allocation extents
detect a merged extent can form a full extent write (e.g., offset and length are both 1MiB aligned)
flush this extent by a worker thread
Implementation and Evaluation
evaluation
setup
cluster
Lustre 2.15.58 with CentOS 8.7
4 MDT, 8 OST, DDN AI400X Appliance
20 * 3.84TiB NVMe
32 client nodes
tool
IOR, mdtest
baseline
BeeGFS
buffered: write-back and read-back using static buffers
native: rely on Linux page cache, switches to DIO via a I/O threshold (512KiB)
OrangeFS
alt-aio: buffered asyn I/O
directio: DIO mode
result
single process I/O streaming
autoIO: achieving the best overall performance over the entire range of I/O sizes
multiple I/O stream throughput
IO500: mdtest-hard, IOR-easy, IOR-hard
VPIC-IO
h5bench
2. Strength (Contributions of the paper)
transparent I/O mode decision within the file system
decision are based on I/O size, lock contention, and cache usage
additional optimizations
implemented in Lustre and extensive experiments
3. Weakness (Limitations of the paper)
consistency challenges
need to clarify in details
does not change Lustre's strong consistency guarantees
4. Some Insights (Future work)
HPC clusters traditionally store data on parallel file systems
Ceph, Lustre, GPFS, PVFS, OrangeFS
new access patterns from ML and AI
increase random accesses and heavy metadata traffic
direct I/O
drawbacks
single-stream: when data cannot be reused multiple times
multiple processes: create many lock conflicts for a shared file with strong consistency guarantees
advantages
avoiding a "double buffer" situation, when an application itself buffers read and write operations
e.g., database
do not need to deal with I/O size and alignment constraints
hide the latency of slow storage accesses
when data is accessed more than once
buffered I/O
drawbacks
additional copy operations
move data between the kernel cache and the application
kernel page cache and page management
when memory become scarce
page reclamation must free old pages to allocate memory for the current I/O operation
cache thrashing
in parallel file systems
need to manage complex distributed range locks to support client-side caching with strong consistency
advantages
reduce CPU utilization for file reads and writes
eliminating the copy from the cache to the user buffer
minimizing the number of lock revocations
page cache management
during memory pressure
reclaiming pages requires not only evicting pages from the page
also writing the data back to the storage system
pagecache_get_page()__set_page_dirty_nobuffers()
Lustre lock
lock covering the required I/O range (aligned with the page size)
optimization
expanding the lock to the largest non-conflicting range
reduce lock traffic based on principle
result in heavy lock contention, false lock sharing for concurrent writes on a shared file
revoke --> flush the dirty pages to the server, clears the client cache, and release lock
locks cached by a client
not released immediately
ior-hard-write
each MPI rank concurrently writes into a single shared file
with an I/O size of 47,008 bytes in strided I/O mode
HPC benchmark