The Dilemma between Deduplication and Locality: Can Both be Achieved?
| Venue | Category |
|---|---|
| FAST'21 | Deduplication System Design |
The Dilemma between Deduplication and Locality: Can Both be Achieved?1. SummaryMotivation of this paperMFDedupImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some Insights (Future work)
1. Summary
Motivation of this paper
Motivation
restore and GC issues in deduplication system
- locality issue
- eliminate random I/O
most duplicate chunks in a backup are directly from its previous backup.
- a novel management-friendly deduplication framework
- Neighbor-Duplicate-Focus indexing (NDF): perform duplicate detection against a previous backup.
- Across-Version-Aware Reorganization scheme (AVAR): rearrange chunks with an offline and iterative algorithm into a compact, sequential layout.
GC issues
includes two stages:
- selecting which containers have unreferenced chunks
- migrating referenced chunks into new containers, so selected containers can be freed
The main difference between previous deduplication system
previous deduplication system: write-friendly, mainly focus on write path, rarely manages the location and placement of chunks
this deduplication system: management-friendly, use offline method to iteratively redesign the data layout of deduplicated chunks to improve chunk locality.
- argue the cost of this offline approach is acceptable.
MFDedup
Main observation
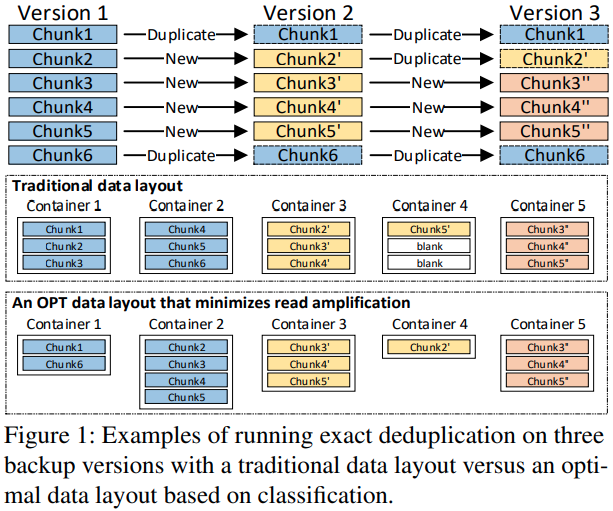
Fragmentation is dependent on the backup version and associated with chunks' reference relationship.
can use this to reduce the fragmentation issue (classification-based data layout)
- change to variable-sized containers
Main challenges
The space of classification is very large, may generate more small containers
- 2^n - 1 categories, (n is the number of versions)
OPT data layout solves the read amplification problem but requires more seek operations for these very small containers, which causes poor data locality.
Derivation relationship of backups
In backup system, the duplicate chunks of each backup are not randomly distributed but are derived from the chunks of the last backup
- consecutive pattern of duplicates
- adjacent and internal duplicate chunks account for more than 99.5% in most datasets
can greatly decrease the number of categories needed for the OPT data layout.
Neighbor-Duplicates-Focus indexing (NDF)
only removes duplicates between neighboring backup version.
need to build a local fingerprint index
- lower memory overhead compared with traditional global fingerprint index.
- current version and previous version
Across-Version-Aware reorganization (AVAR)
Deduplicating stage: store unique chunks of the latest new backup version into a new active category.
- chunks in active category may be referenced by future backup versions
Arranging stage: analyze the reference relationship between chunks and backup versions.
- need to iteratively update the existing OPT with new unique chunks of the incoming version.
Each category has two states:
Active: can be further arranged after future backups.
Archived: immutable.
Grouping: store the new archived categories into a Volume by the order of their name
- achieve sequential reads during the restore process
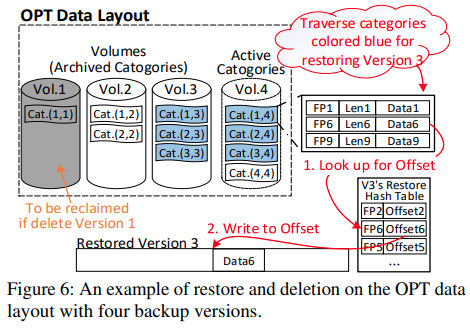
Restore
need to read the required categories on the OPT data layout, which is referenced by the to-be-restored version.
- Grouping: required categories are always grouped in the same volume ↪️ sequential reads.
Deletion and GC
- delete the last category in the corresponding volume.
Implementation and Evaluation
Implementation:
based on Destor, open-sourced
SHA-1 as the fingerprint
FastCDC: as the chunking method
Compared with:
- HAR: History-Aware rewriting algorithm (FAST'14)
- CAM: Container-Marker algorithm (TPDS'14)
- Capping: FAST'13
Evaluation
Trace: sina, source code of Chromium project, ubuntu VM, SYN
SSD user space + HDD store space
Actual deduplication ratio
- compare with exact deduplication and other rewrite scheme
Backup throughput
- hashing is the bottleneck
- indexing overhead is better than keeping a global index
Restore throughput
- Restore throughput
- Seek number
- Read amplification factor
Arranging vs. Traditional GC
- compared with Perfect GC
- processing period (s)
Size distribution of volumes/categories
the size of volumes: 90MB - 1.3GB
can estimate how much more can be written to the deduplication system
- volumes represent the difference between neighboring versions.
2. Strength (Contributions of the paper)
- Neighbor-Duplicate-Focus (NDF) indexing: only detect duplicates of a backup version with its previous version
- Across-Version-Aware Reorganization (AVAR): classify and group according to the simplified reference relationship between chunks and versions.
- Good discussion in the limitation of current prototype.
3. Weakness (Limitations of the paper)
- This paper only considers two state-of-art rewriting techniques, however, there exists many works to solve the rewriting issues (FAST'18, FAST'19)
capping-FAST'13 HAR -FAST'14
4. Some Insights (Future work)
- Why focuses on hard-drive based deduplication
For backup storage, it remains one of the most significant use cases.
- Key insights
change the container from fixed-sized containers to variable-sized containers
- the discuss of the backup size:
VM backups: 100GB
the majority of backups are 50-500GB in Data Domain.