Probabilistic Deduplication for Cluster-Based Storage Systems
| Venue | Category |
|---|---|
| SoCC'12 | Distributed Deduplication |
Probabilistic Deduplication for Cluster-Based Storage Systems1. SummaryMotivation of this paperProDuckImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Some Insights (Future work)
1. Summary
Motivation of this paper
Integrating deduplication into cluster-based backup solution is a challenging task.
- maximizing deduplication
- balancing the storage load on the available nodes
Countermeasure
- stateless solutions: assign data to nodes based only on the observation of the content of the chunk of data being stored.
- stateful solutions: maintain information about currently stored data in order to assign identical data blocks to the same node.
- Key question The overhead of stateful solutions is very high which makes them impractical. How to make practical stateful system becomes available.
ProDuck
Architecture
- Coordinator node: it is responsible for managing the requests of clients, determining which StorageNode should store each chunk of a given file.
- Coordinator implements novel chunk assignment and load balance strategies
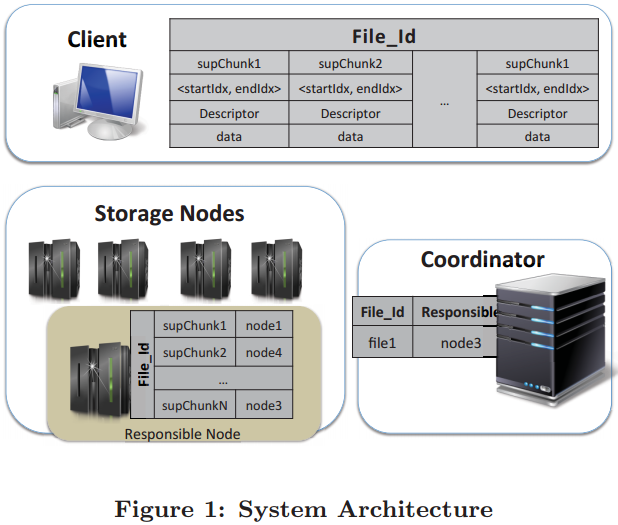
Chunking
- content-based chunking
- Group contiguous chunks into large superchunks when storing data onto storage nodes. (content-defined, checking the fingerprint of the last chunk)
- average superchunk size of 15 * 1024 chunks
Chunk Assignment
- Assign superchunks to StorageNode so as to maximize deduplication. This assignment is carried out by the Coordinator through a novel chunk-assignment protocol.
- key observation: to choose the StorageNode offering the highest deduplication rate for a given superchunk, the protocol does not need to know exactly which chunks are stored on each StorageNode.
- it only needs the overlap between the chunks on each StorageNode and those in the superchunk to be stored.
- Probabilistic multiset intersection ProDuck uses PCSA to estimate the cardinality of a multiset. And this can extend to estimate the cardinality of the union of two multisets.
simply applying the bitwise OR operator on the two corresponding bitmap vectors.
- Maintaining chunk information multiset:
- each superchunk.
- multiple superchunks stored in StorageNode.
The coordinator stores a bitmap vector for each StorageNode
64KB for each StorageNode minimal space requirements
Update when receiving a bitmap vector of the incoming superchunk.
- Choosing the best storage node calculating the overlap between the node's content and a superchunk.
update the corresponding the bitmap of the determined storage node.
Also consider the data locality in backup workload:
rank the top StorageNode according to their overlaps, check if the node that stored the previous superchunk in the file is among these .
- Load Balancing
- Using bucket-based load-balancing strategy
splitting the storage space of each node into fixed-size buckets.
The coordinator grants the StorageNode a new bucket only if doing so would not exceed the number of buckets allocated of the least loaded node by more than one.
Implementation and Evaluation
Evaluation
- Dataset: Wikipedia snapshot (publicly available for download), private dataset.
- Baseline: BloomFilter (stateful), MinHash (stateless),
- BloomFilter (stateful) the Coordinator maintains a bloom filter for each storage node an index of the node's contents.
the decision of storing a new superchunk takes into account the location of existing ones.
- MinHash (stateless) select the minimum hash of the chunks in a superchunk as the superchunk's signature.
Metrics
- Total Deduplication: the original size of the dataset and its size after being deduplicated. (compare with the optimal case of a single-node system with no load-balancing constraints)
- Data Skew: the occupied storage space on the most loaded node to the average load in the system
- Assignment Time: the time of each strategy to assign all the dataset to the available nodes.
- varying the node number of the cluster
- Sensitivity analysis
- superchunk size
- bucket size
- maximum allowed bucket difference
2. Strength (Contributions of the paper)
- this paper proposes a lightweight probabilistic node-assignment mechanism
quickly identify the servers that can provide the highest deduplication rates for a given data chunks.
- a new bucket-based load-balancing strategy
spreads the load equally among the nodes.
3. Weakness (Limitations of the paper)
- the rationale of its bucket-based load-balancing algorithm is not very clear. I do not understand why it can outperform than it counterparts.
- Also, there are some system parameters which need to be configured and may impact the result. For example, the superchunk size. How to automated configure those parameters for different workloads is still unclear.
4. Some Insights (Future work)
- In this work, the two key issues are
1) how to determine the storage node for each incoming superchunk to achieve better deduplication ratio? 2) how to achieve the load-balancing under the above objective?
For the first issue, the key is have to design a data structure to track the content of each storage node.
probabilistic counting, set intersection