Can't We All Get Along? Redesigning Protection Storage for Modern Workloads
| Venue | Category |
|---|---|
| USENIX ATC'18 | Redesign Deduplication |
Can't We All Get Along? Redesigning Protection Storage for Modern Workloads1. SummaryMotivation of this paperNew DDFSImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Future Works
1. Summary
Motivation of this paper
- Considering the impact of evolving workloads on system performance on Data Domain File System (DDFS) as a whole.
- the impact of increasing numbers of small files
- higher deduplication ratios
- Garbage collection (GC) was slowed by these changing workloads
need new algorithms
A new requirement is particularly demanding
involves large amounts of nonsequential I/O (NSIO)
- Therefore, this paper argues that they are at an inflection point.
need to rethink and redesign backup systems to enable optimizaed performance for non-traditional data protection workloads with nonsequential accesses.
New DDFS
- Traditional workloads and Non-traditional workloads
- Traditional workloads: large sequential writes and reads with low metadata operations
- Nontraditional workloads: have many small files, more metadata operations, and frequent non-sequential accesses.
- Deduplicating protection storage Each file is represented by a Merkle tree.
- Key Improvement motivation Moving the index to SSDs was a necessary step to improve performance.
- Changing environments
- Data format: traditionally, treat the backup as tar format (cannot restore an individual files inside of it)
a shift towards backing up individual files in their "native" format lead to millions or billions of individual fils (metadata overhead)
- Unit of deduplication: need to consider the application knowledge
variable-size chunk or fixed-size chunk? need to align the unit of deduplication appropriately.
- Devices: SSD caching
how to retrofit this to an existing disk-based data protection system.
- Mixed workloads: DDFS was originally designed to support large sequential access patterns
currently, need to support both sequential accesses and random accesses in the workload.
- SSD caches
- Fingerprint Index Cache (FPI) fingerprint to container index (location in storage)
to support NSIO, the system keeps the entire FPI in SSD. Since space is limited, it just store a short hash (4 bytes) rather than long hash (20 bytes)
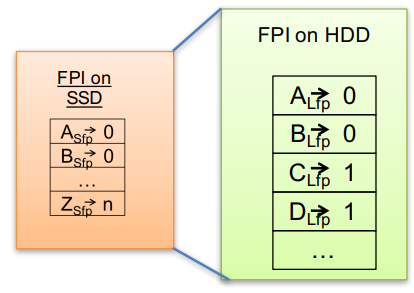
Short fingerprints would introduce the false positive (match is incorrect) (can be detected)
if the needed chunk is not found in the container referenced by the short fingerprint, then the full on-disk index is consulted. (latnecy is high, while this case is infrequency)
Can receive more improvement when the locality is bad.
- File Metadata Cache (FMD)
- Chunk Data Cache The main difference:
- the locality of access within a contianer may be highly variable, and the reuse of specific data may by more commonplace.
- a data chunk might be written and then read, with a gap between the accesses that would be too large for the data to reside in a client or server DRAM cache.
- Directories Cache mapping file path to Merkle tree
- For large files such VM image, the lookup overhead is insignificant.
- But for modern workload where it includes many small files, the directory lookup becomes significant performance penalty.
A full copy of directory manager is now cached in SSD for performance.
straightforward, DM is allocated 5% of the SSD cache.
- File system modifications to support nonsequential workloads Goal: software optimizations remove unnecessary I/Os to disk
- Detecting workload type To decide whetehr NSIO processing is needed.
partition large files into regions and keeps a history of recent I/Os per region if a new I/O is not within a threshold distance of one of the previous 16 I/Os, it is considerd nonsequential.
- QoS and throttling
split the backup and restore workload shares into sequential and nonsequential shares when meet RPC timeouts, I/O throttling per workload (implement an edge throttling mechanism)
- selective fingerprint index queries it chooses to skip redundancy checks to improve performance
nonsequential writes tend to consist of unique content disable query the fingerprint index for small nonsequential writes (<128KB) Any duplicate chunks will be removed during periodic garbage collection
- Delay metadata update switch to fixed-sized chunks (for efficient updates of file recipes during nonsequential writes)
need to update the file recipe to reference new chunks (delay until sufficient updates have been accumulated)
- Direct read of compression regions change the mapping of fingerprints to container
to fingerprint to container and compression region index (reduce the index lookup I/O) Reason: for NSIO, feature accesses are unlikely to remain within the same container.
- Adjust the chunk size to improve nonsequential writes Although variable-sized chunking has better deduplication, the performance gains achieve with fixed-size chunks outweighs the deduplication loss.
new use cases that have block-aligned writes
Implementation and Evaluation
- Evaluation Focus on average IOPS and latency
- without SSD cache + without software optimization
- SSD cache metadata + without software optimization
- SSD cache data and metadata + without software optimization
- SSD cache data and metadata + software optimization
2. Strength (Contributions of the paper)
- This paper extends support to modern backup applications with NSIO access patterns.
benefit both traditional and non-traditional backup and restore tasks
- propose some optimized technologies to better utilize the benefits of flash
selectively storing metadata on SSDs.
3. Weakness (Limitations of the paper)
4. Future Works
- This paper mentions the change of workload in deduplication system
NSIO and SIO, using SSDs for caching metadata combining SSD caching with software optimizations throughout its system
- Main contribution: add SSD cache + software optimization
- DDFS has had to evolve to support not only traditional workloads (sequential backup worload)
support also newer non-sequential workloads. (direct access for reads and writes in place) expect NSIO workloads to become more common as customers increase the frequency of backups.