RevDedup: A Reverse Deduplication Storage System Optimized for Reads to Latest Backups
| Venue | Category |
|---|---|
| ACM APSys'13 | Deduplication Restore |
RevDedup: A Reverse Deduplication Storage System Optimized for Reads to Latest Backups1. SummaryMotivation of this paperRevDedupImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Future Works
1. Summary
Motivation of this paper
Deduplication introduces fragmentation that degrades read performance. This paper proposes RevDedup which can optimize reads to the latest backups of VM images via reverse deduplication.
Idea: shift fragmentation to old data while keeping the layout of new data as sequential as possible.
Some assumptions
- Today's backup solutions mainly build on disk-based storage.
- A fast restore operation can minimize the system downtime during disaster recovery.
- Users are more likely to access more recent data.
RevDedup
- Key insight Traditional deduplication systems check if new blocks can be represented by any already stored blocks with identical contents.
The fragmentation problem of the latest backup is the most severe since its blocks are scattered across all the prior backups.
To mitigate this impact, this paper proposes to do the opposite deduplication.
check if any already stored blocks can be represented by the new blocks to be written. keep the storage layout of the newer backups as sequential as possible.
- System Design
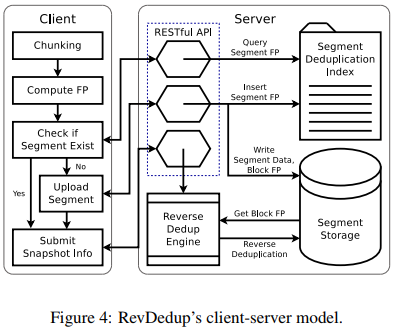
- Client-sever model:
- a server stores deduplicated VM images and the deduplication metadata
- multiple clients run the active VMs
- Fix-size chunking
- have smaller chunking overhead than variable-size chunking.
- Coarse-grained global deduplication
- apply deduplication to large fixed-size units called segmemts, (several megabytes)
- inside single versions VM across different versions VM across different versions VM in different machines.
- large segment size can amortize disk seek while still achieves high deduplication efficiency.
- Fine-Grained Reverse Deduplication
- Remove the any duplicates in older versions, and use indirection.
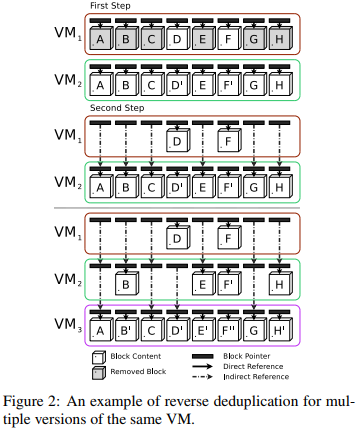
- Only compare the two most recent versions and (may loss some saving space)
- Reference Counting:
indicates the number of direct references that currently refer to the block among all versions of the same VM or different VMs.
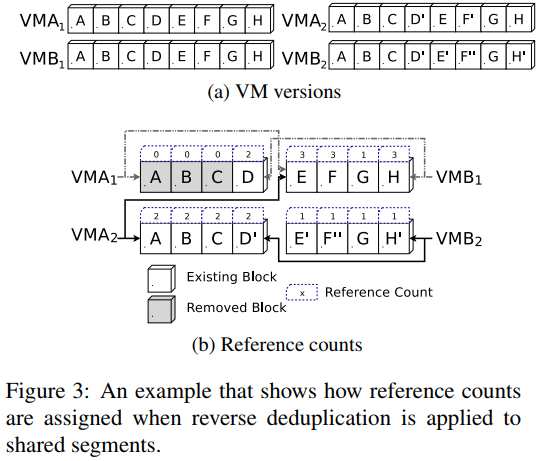
- Some optimized methods Block punching: hole-punched region, and implement via fallocate() in file system. Segment compaction: compact a segment that excludes the removed blocks.
uses a pre-defined threshold (namely, rebuild threshold) to determine how to determine how to rebuild a segment excluding removed blocks. rebuild threshold is configured to trade between disk fragmentation and segment copying time.
- Indexing Segment index is in-memory (fingerprint and other metadata ---- each segment)
argue that the index has low memory usage when using large-size segments. SHA-1 for block fingerprints and segment fingerprints
The metadata of each block in each segment is stored in disk.
fingerprints and reference counts of each block
Implementation and Evaluation
- Imlementation Offload the server by having the clients be responsible for both segment and block fingerprint computations.
Multi-threading Communication: RESTful APIs
- Evaluation Prove: high deduplication efficiency, high backup throughput, high read throughput. Dataset: local VM datasets (160 VM images)
- Storage efficiency Similar to conventional deduplication ratio (96%)
- Backup throughput Conventional deduplication backup throughput (30% loss)
- Read throughput achieve the design goal, improve the restore performance of latest backup.
2. Strength (Contributions of the paper)
- This paper is very clear, and its idea is very simple but novel, and can improve the restore performance for latest backup.
- The system design is very comprehansive.
3. Weakness (Limitations of the paper)
- This paper just focuses on latest backups which is not very general.
4. Future Works
- This paper just assumes users are more likely to access more recent data, if we weak this assumption to a general case, how to change this method to improve the shift the fragmentation evenly?
- Also, how about the variable-size chunking?