SS-CDC: A Two-stage Parallel Content-Defined Chunking for Deduplicating Backup Storage
| Venue | Category |
|---|---|
| SYSTOR'19 | Deduplication Chunking |
SS-CDC: A Two-stage Parallel Content-Defined Chunking for Deduplicating Backup Storage1. SummaryMotivation of this paperSS-CDCImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Future Works
1. Summary
Motivation of this paper
- To complete backing up of a large amount of data within a tight time window, the system has to provide sufficiently high backup performance.
deduplication adds the significant performance overhead to the system (variable-size chunking process) it needs to calculate a hash value for the rolling window at almost every byte offset of a file, which consumes significant CPU resource and has become a performance bottleneck in many backup storage system.
- Chunking invariability To accelerating CDC-based deduplication, it can partition an input file into segments, and leverage parallel hardware.
chunking invariability requires a parallel chunking algorithm always generates the identical set of chunks independent of the parallelism degree and the segment size. However, many parallel CDC algorithms do not provide this guarantee. (different from sequential CDC)
This paper porposes a two-stage parallel CDC which enables full parallelism on chunking of a file without compromising deduplication ratio.
further exploits instruction-level SIMD parallelism, offload chunking to SIMD platforms. guarantee the chunking invariability
SS-CDC
- Chunk boundary A chunk boundary is determined when two conditions are met:
- the chunk is within the range of pre-defined value.
- the hash value of the rolling windom matches a pre-defined value.
- Original CDC chunk process is sequential The process of determining a sequence of boundaries in a file is inherently sequential, as declaration of a new boundary depends on:
- the hash value of current rolling window
- the previous boundary's position
- Main Idea the chunking process can be separated into two tasks:
- rolling window computation: generate all potential chunk boundaries (expensive + parallel)
- select chunk boundaries out of the candidate ones so that meets the chunk size requirements (lightweight + serialized) Goal: generate the identical set of chunk boundaries and the same deduplication ratio as the sequential CDC.![1560263818057]
- Two-stages of SS-CDC algorithm
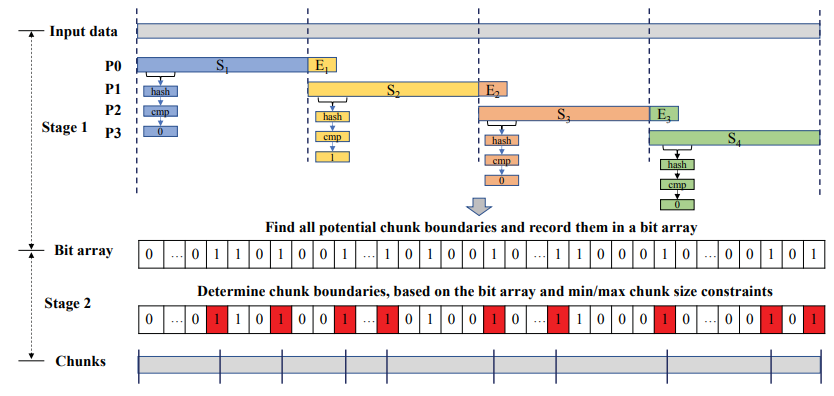
First stage: find the candidate boundary via rolling hash, produces a set of chunk boundary candidates which statisfy the first condition.
the result is record in a bit array. Multiple bits can be set simultaneously using SIMD instructions without using locks.
Second stage: select the final chunk boundaries from the candidates, which can meet the minimum and maximum chunk size constraints. For an input data with bytes, the output bit array will be of bits.
- a bit '1' at the bit-offset in the bit array indicates a chunk boundary candidate at the byte-offset in the input file.
- scanning from its beginning, searching for the '1' bits that meet the minimum and maximum chunk size constraints. These offsets are the final chunk boundaries.
- Paralleling Operations in SS-CDC
- The first stage can be paralleled by assigning a different thread for each segment.
- The second stage must be performed by sequentially to find the next chunk boundary which meets the minimum and maximum chunk size constraints.
How to improve? the bit array comtains mostly '0' bits, with only a few '1' bits, can regard it as 32-bit integer, if that integer is non-zero, a bit-by-bit checking is needed.
- Integrate with AVX-512 use an AVX register to store all values of all current rolling windows (one for each segment)
use some AVX instruction to accelerate the speed.
- Sacle to multiple cores A chunking thread is started at each core, and retrieves a batch of segments each time from the head of the queue for the first stage chunking
a lock is required to enforce an exclusive access to the queue.
Implementation and Evaluation
- Evaluation Datasets:
- Linux source codes: from Linux Kernel Archives (transform tar mtar)
- Docker Hub image: each image is tar file
- Chunking speed compared with sequential CDC with one thread running on one core
400MB/s 1500MB/s (3.3 ) achieved by leveraging the instruction-level parallelism
Minimum chunk size also impacts the speed up of SS-CDC.
- The case of multiple cores for multiple files Multithreading of single file suffers from the same bottlenecks
as the use of a lock at the segment queue, barrier synchronization at the end of the first stage.
2. Strength (Contributions of the paper)
- identify the root cause fo the deduplication ratio degradation of existing parallel CDC methods
provide quantitative analysis
- This is the first work to use Intel AVX instructions for parallel chunking.
- The key contribution of this work: SS-CDC guarantees chunking invariability and achieves parallel chunking performance without impacting deduplication ratio.
3. Weakness (Limitations of the paper)
- SS-CDC actually needs to read more data and do more rolling hash calculation than sequential chunking.
it does not skip the input data using the minimum chunk size. SS-CDC has to scan and calcualate a hash for every byte.
4. Future Works
- This paper catches two limitations of the current parallelized chunking algorithms
chunking invariability cannot take advantage of instruction-level parallelism offered by the SIMD platforms. (frequent branches)