A Simulation Analysis of Redundancy and Reliability in Primary Storage Deduplication
| Venue | Category |
|---|---|
| TC'18 | Deduplication Reliability |
A Simulation Analysis of Redundancy and Reliability in Primary Storage Deduplication1. SummaryMotivation of this paperMethod NameImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Future Works
1. Summary
Motivation of this paper
- Despite the wide adoption of deduplication, how deduplication affects storage system reliability remains debatable when compared without deduplication.
mitigate the possibility of data loss by reducing storage footprints. amplifies the severity of each data loss event, which may corrupt multiple chunks or files that share the same lost data.
- State-of-art countermeasures:
add redundancy via replication or erasure coding to post-deduplication data. propose quantitative methods to evaluate deduplication storage reliability.
- two key open reliability issues:
loss variations: different failures (device failures, latent sector errors), different granularities of storage (chunk, files) repair strategies: repair strategies determine whether import data copies are repaired first (affect reliability in different ways)
- Main motivation The importance of analyzing and comparing storage system reliability with and without deduplication.
Method Name
- Choose dataset
- FSL: pick nine random snapshots with raw size at least 100GB each
Mac OS X server: user011 - user026 (eight users): taken from different users' home directories with various types of files.
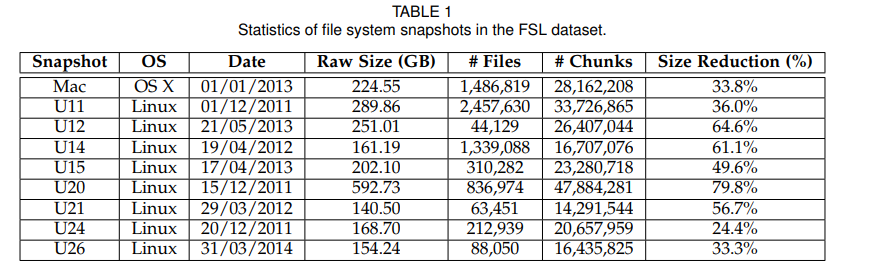
- MS: collected at Microsoft and publicized on SNIA. Focus on a total 903 file system snapshots taht are collected in a single week
time: September 18, 2009 the average chunk size: 8KB
Also, consider the notion of a deduplication domain (a set of file system snapshots over which it performs deduplication).
deduplication domain size specifics the number of file system snapshots included in a deduplication domain generate 10 random deduplication domains for each deduplication domain size.
- Redundancy analysis
- Reference counts Intuition: the important of a chunk is proportional to its reference count.
the majority of chunks have small reference counts. (e.g., referenced by exactly once) losing the highly referenced chunks may lead to severe loss of information as well as high deviations in the reliability simulations.
- How to determine similar files?
- share the same minimum chunk fingerprint (Minhash, Broder's theorem)
- share the same maximum chunk fingerprint
- have the same extension (provide an additional indicator if the two files are similar)
FSL shows significant fractions of intra-file redundancy. The most common redundancy source are duplicate files
whole-file deduplication is effective.
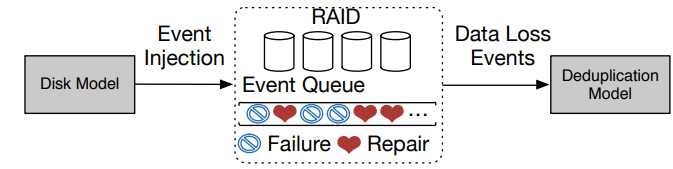
- Simulation framework Design a framework which analyzes and compares storage system reliability with and without deduplication. Need to configure those factors:
- failure patterns
- metadata
- data layout
- Deliberate copy technique Based on the key observation:
Highly referenced chunks only account for a small fraction of physical capacity after deduplication the chunk reference counts show a long-tailed distribution It is possible to allocate a small dedicated physical area for storing extra copies of highly refenced chunks
Solution:
- allocate the first 1% of physical sectors for the highly referenced chunks
- sort the chunks by their reference counts, and fill the dedicated sectors with the top 1% most highly referenced chunks.
do this process offline (no need to change the write/read path) incur moderate stroage overhead
Implementation and Evaluation
- Evaluation
- observation-1 Deduplication will significantly alter the expected amounts of corrupted chunks by USEs when compared to without deduplication.
- observation-2 The logical repair progress is affected by the placement of highly referenced chunks and the severity of chunk fragmentation.
- observation-3 If it does not carefully place highly referenced chunks and repair them preferentially, deduplication can lead to more corrupted chunks in the presence of UDFs.
2. Strength (Contributions of the paper)
- This paper studies the redundancy characteristics of the file system snapshots from two aspects:
the reference counts of chunks the redundancy sources of duplicate chunks minimum hash is better to determine similar files losing a chunk may not necessarily imply the corruptions of many files
- propose a trace-drvien, deduplication-aware simulation framework to analyze and compare storage system reliability with and without deduplication.
- apply this simulation framework and get some key findings of its reliability analysis.
3. Weakness (Limitations of the paper)
4. Future Works
- This paper mentions Highly referenced chunks occupy a large fraction of logical capacity, but only a small fraction of physical capacity after deduplication.
skew distribution. can assign a small dedicated physical area (with only 1% of physical capacity) for the most referenced chunks and first reparis the physical area to improve them. (incurring only limited storage overhead)
- Main sources of duplicate chunks
- intra-file redundancy
- duplicate files
- similar files