Sketching Volume Capacities in Deduplicated Storage
| Venue | Category |
|---|---|
| FAST'19 | Sketch+Deduplication |
Sketching Volume Capacities in Deduplicated Storage1. SummaryMotivation of this paperVolume SketchImplementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Future Works
1. Summary
Motivation of this paper
This work focuses on technologies and tools for managing storage capacities in storage system with deduplication.
analyzing capacities in deduplicated storage environment reclaimable capacity, attributed capacity
The key issus: once deduplication is brought in to the equation, the capacity of a volume is no longer a known quantity.
for any single volume or any combination of volumes
This work addresses gaps for reporting and management of data that has already been deduplicated, which prior works do not address.
Volume Sketch
- Main idea: the decision to forgo the attempt to produce accurate statistics
This paper borrow techniques from the realm of streaming algorithms (sketch)
the metadata of each volume is sampled using a content-based sampling technique to produce a capacity sketch of the volume. key property: sketch is much smaller than the actual metadata, yet contains enough inoformation to evaluate the volumes capacity properties.
- Capacity sketches
- choose samples of the metadata according to the respective data content.
for each data chunk, examine its fingerprint (the hash), and include it in the sketch only if it contains leading zeros for a parameter Sample ratio: , also called sketch factor. this is the tradeoff: the required resources to handle the sketches vs. the accuracy which they provide.
- using sketches for data inside a deduplication system Maintain at all time a full system sketch
representing all of the data in the system
It also collects further parameters in the sketch
Reference count: the number of times the data chunk with fingerprint was written in the data set Physical count: the number of physical copies stored during writes to the data set .
- Attributed capacity and data reduction ratios Those information can let the adminstrator to understand the data reducation properties of volumes.
how much is a volume involved in deduplication attributed capacity: a breakdown of a volume of its space savings to deduplication and compression. For example: if a data chunk reference is 3, 2 originating from volume and one from volume , then the space is split in a and fashion between volume and respectively.
- Accuracy guarantee
- Chernoff Bound
- Bernoulli variables
Very similar to the MSST'12's work
- System architecture
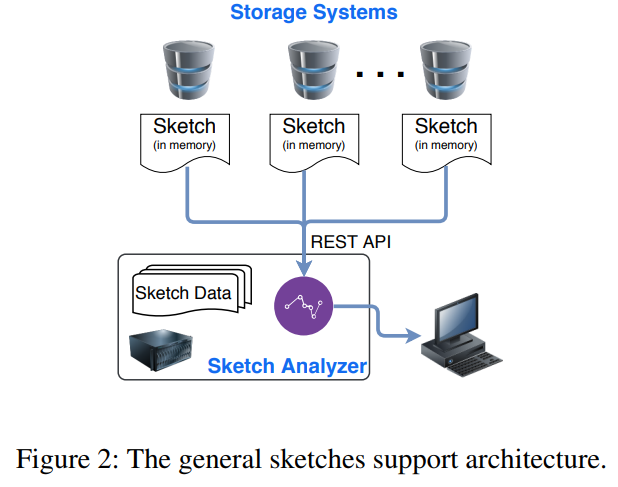
pull the sketch data out of the storage system onto an adjacent management server where the sketch data is analyzed.
this avoid using CPU and memory resources in the storage that could otherwise be spent on serving I/O requests.
- All sketch data is held in memory at all times. (allow to retrieve the data swiftly)
- Each process is in charge of serving IOs for slices of the entire virtual space.
each slice has its own sketch which is maintained by the owning process.
- The sketch portrays the state of a slice at a point in time.
- A central process contacts all processes and retrieves their respective sketch data.
Implementation and Evaluation
- Architecture and implementation
- Sketch analyzer
Ingest phase: for each volume, it collects all of its relevant hashes while merging and aggregating multiple appearances of hashes.
- a full system hash table: all of the hashes seen in the full system
- volume level structures: A B-Tree for each volume in the system which aggregates the hashes (only store a pointer to the entry in the full table)
- Evaluation Dataset:
- Synthetic data: using VDBench benchmarking suite
- UBC data traces
- Production data in the field
- Ingest and analyze performance
- Group query performance
- Estimation accuracy
2. Strength (Contributions of the paper)
- This work enables to query reclaimable capacities and attributed capacities for any volume in the system
- It can also answer how much physical space such a volume/group would consume if it were to be migrated to another deduplicated storage system.
- It also discusses the accuracy guarantees of the sketch method.
3. Weakness (Limitations of the paper)
4. Future Works
- This paper mentions that there a number of reasons for a chunk to have more than a single physical copy in a system.
deduplication opportunities that were not identified the choice to forgo a deduplication opportunity for avoiding extensive data fragmentation
- This paper mentions that the sketch provides a fuzzy state, when it actually obtains the sketch for the last slice, the sketch in the system for the early slices might have changed.
This is an inaccuracy that the storage systems are dynamic and it cannot expect to freeze them at a specific state. It needs to reduce the time window in which the sketches are extracted.
- This paper mentions that under the randomness of SHA-1, a false collision of 8 bytes in the sketch data would occur on average once on every 256PB
- For sharding, due to the randomness of the hash function, it is expected that each such partition will receive a fair share of the load.
sketch distribution and concurrency