dedupv1: Improving Deduplication Throughput using Solid State Drives (SSD)
| Venue | Category |
|---|---|
| MSST'10 | Deduplication |
dedupv1: Improving Deduplication Throughput using Solid State Drives (SSD)1. SummaryMotivation of this paperdedupv1Implementation and Evaluation2. Strength (Contributions of the paper)3. Weakness (Limitations of the paper)4. Future Works
1. Summary
Motivation of this paper
The limited random IO performance of hard disks limits the overall throughput of deduplication system
if the index does not fit into main memory
The size of the chunk index limits the usable capacity of the deduplication system.
8KB chunk size, 20 byte fingerprint: 1TB data 2.5GB chunk index It becomes necessary to store the fingerprint index on disk.
This paper wants to use solid-state drives (SSDs) to improve its throughput compared to disk-based systems.
However, most current SSDs suffer from slow random writes. Its design proposes to avoid random writes on the critical data path. The weak point of SSDs is the limited number of random writes.
dedupv1
- System architecture
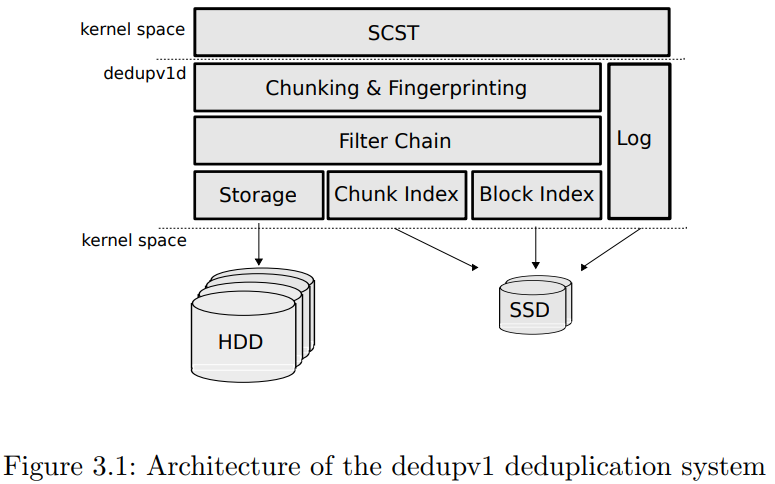 The data deduplication is transparent to the user of the SCSI target.
The data deduplication is transparent to the user of the SCSI target.
- Chunking and Fingerprint Each chunk is fingerprinted after the chunking process using a cryptographic hash function.
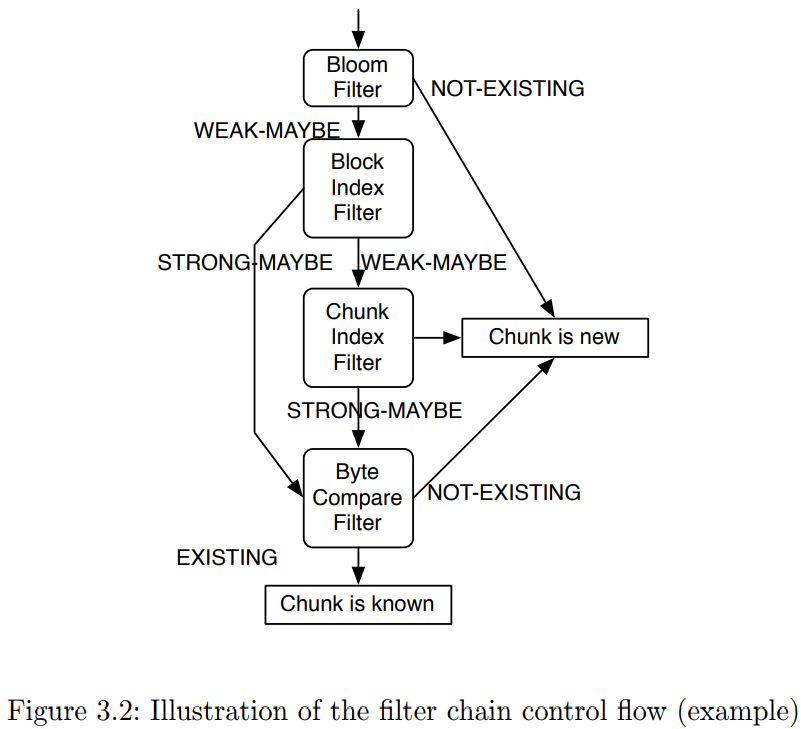
- Filter chain state The file chain can execute a serirs of filters
after each filter step, the result of the filter determines which filter steps are executed afterwards.
EXISTING: the current chunk is an exact duplicate STRONG-MAYBE: there is a very high probability that the current chunk is a duplicate
a typical result after a fingerprint comparison.
WEAK-MAYBE: the filter cannot make ant statement about the duplication state of the chunk. NON-EXISTING: the filter rules out the possibility that the chunk is already known.
- Filter implementations
- Chunk index filter
- Block index filter
- Byte compare filter
- Bloom filter
- Container cache filter
- Chunk index Auxiliary chunk index stores chunk entries for all chunks whose containers are not yet written to disk as such chunk entires are only allowed to be stored persistently after the chunk data is committed.
take index writes out of the critical path if the auxiliary index grows beyond a certain limit or if the system is idle, a background thread moves chunk metadata from the auxiliary index to the persistent index.
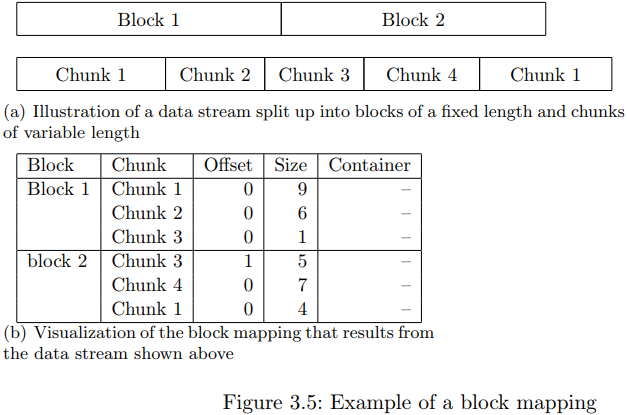
- Block index It stores the metadata which is necessary to map a block of the iSCSI device to the chunks of varying length that from the most version of the block data.
a block mapping contains multiple full chunks.
- Log Two goals
- recover from system crashes: just replay
- delay write operations Also helps to delay may write operations
the amount of IO operations in the critical path is minimized because the log assures that the delayed operations can be recovered.
Implementation and Evaluation
- Evaluation
- distinguish the first backup generation and further backup generation
Generate first backup generation: 128GB subset of files Generate second backupo generation based on the first backup generation
- evaluate the throughput using different index storage systems
2. Strength (Contributions of the paper)
- the key novelty of this paper is it uses the auxiliary chunk index to store chunk entires for chunks whose containers are not yet written to disk.
take index writes out of the critical path. delay the IO such that the update operations can be done outside the critical path.
3. Weakness (Limitations of the paper)
- this idea of this paper is not novel.
4. Future Works
- This paper shows that it is possible to build a deduplication system using SSDs that can provide a higher performance.
- A key insight in this paper is it leverages a filter chain to find the exact duplicate chunks, instead of directly using the "compare-by-hash"